Authors: pop
tldr; this proposal reduces the bandwidth consumption of PeerDAS by 56.2%
- Since this proposal is an improvement to PeerDAS. Familiarity with PeerDAS is required.
- Topic observation is a building block of this design so it would be helpful if you read it first.
Currently GossipSub imposes an amplification factor on the bandwidth consumption to PeerDAS, since more than one peers can send you the same columns. In fact, you need only one copy, so this amplification wastes your bandwidth.
Previously we have IDONTWANT implemented which reduces the number of copies you will receive, but it doesn’t guarantee exactly how many.
This proposal enables nodes to receive only one copy of most of their sampled columns.
Current bandwidth consumption
(For simplicity, let’s assume that DATA_COLUMN_SIDECAR_SUBNET_COUNT and NUMBER_OF_CUSTODY_GROUPS are equal to NUMBER_OF_COLUMNS)
Let S be SAMPLES_PER_SLOT, C be the size of a column, and D be the amplification factor of GossipSub (aka the mesh degree).
Nodes are required to subscribe to and sample S columns, so each node has to consume the bandwidth about D*S*C bytes per slot.
New design
Previously, we have each node subscribe to S GossipSub topics. Now, we subscribe to fewer topics than that. We have each node subscribe to K=2 topics which is lower than S. Nodes will still receive or forward D copies in these K topics, but they will receive only one copy and forward no copy for the remaining S-K topics.
The reason that we still need to subscribe to K topics is because we need to provide backbones for the topics as required by topic observations (aka stability of the topics).
The bandwidth consumption of K subscriptions is D*K*C bytes per slot.
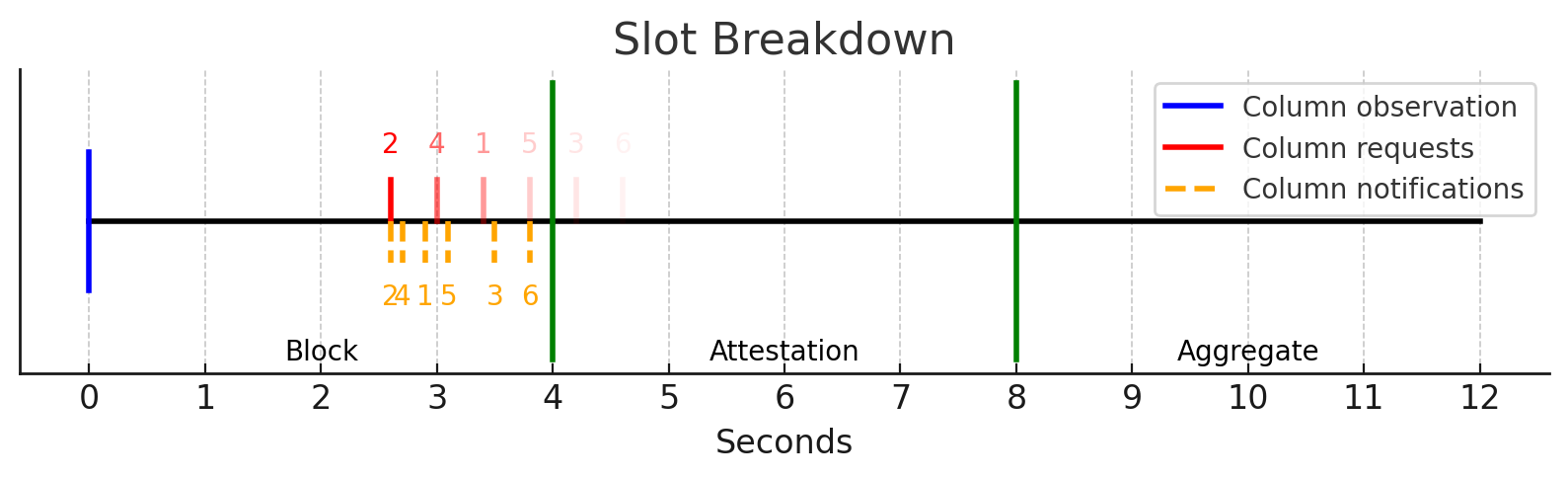
Now, the remaining question is how the node can get the remaining S-K columns that it needs.
Firstly, you start observing the topic at the beginning of the slot (shown as a blue line).
After that, your peers will notify you when there is a new message in the topic. Orange lines show when your peers notify you. Notice that peer 2 is the first one who gets the message (column) and notifies you first.
Since peer 2 notifies you first, you request the actual column from peer 2 with the timeout T (400 ms). After the timeout, if you don’t get it from peer 2, you request it from the peer that notifies you second which is peer 4. If you still don’t get it, you keep going on. Red lines show when you request the column from each peer. The further lines are lighter to indicate that it’s less probable. Consecutive lines are 400ms apart indicating the timeout.
It looks like timeouts will delay the column reception a lot because with the current PeerDAS you will get the column right at the orange lines which are faster. In fact, it’s not that bad for the following reasons.
- It saves a lot of bandwidth. Imagine that you get a copy of the column at each orange line. That looks very wasteful. With this proposal, you get only one copy at one of the red lines.
- Timeouts are rare. You don’t expect to get many timeouts for the following reasons.
- The network condition is already good. If not, how could your peer notify you that it gets a message?. If you could notify me, so you could also send me the column. If it doesn’t, you can probably de-score it.
- Your peer can send you an early rejection without waiting for the timeout. For instance, if your peer is overloaded and doesn’t want to waste the bandwidth sending you the column, it can just send a rejection to you and you can move forward to another peer quickly.
New bandwidth consumption
- The bandwidth consumption due to subscribing to K topics is D*K*C bytes per slot.
- The bandwidth consumption due to observing and downloading the remaining S-K columns is (S-K)*C bytes per slot.
- The bandwidth consumption due to sending the columns to observing peers is the same as above which is (S-K)*C bytes per slot.
The total bandwidth consumption would be (D*K+2*(S-K))*C bytes per slot.
Assign the parameters with the current assignments in the spec: D = 8, K = 2, and S = 8.
- The bandwidth consumption of the current PeerDAS is 64*C.
- The bandwidth consumption of the new one is 28*C which is 56.2% reduction.
The reason I assign K=2 is because, with 8k nodes and the number of columns of 128, there will be at least 100 nodes in each topic.
Pessimistically, if you think K=2 doesn’t make the topics stable enough, we can go to K=4 and the bandwidth consumption would be 40*C which is still 37.5% reduction.
Comparison to IDONTWANT
You can note that the analysis in the previous sections assumes that you will receive or forward exactly D copies of messages when subscribing to topics.
This is not true with IDONTWANT since it can reduce the number of copies you will receive by sending IDONTWANT to your peers before they send you a copy.
There is a still corner case that IDONTWANT doesn’t help reduce the number of copies at all. Imagine that all of your peers send you the message at the same time (the orange lines are very close to each other), so you don’t have a chance to send IDONTWANT to them in time. So, in this case, you still receive the same number of copies as before. While in this proposal, it’s guaranteed that you will receive only one copy.
However, we can combine this proposal with IDONTWANT to get an even better protocol. Since nodes still subscribe to K topics. IDONTWANT can reduce a lot of bandwidth consumption there.
Comparison to Peer Sampling
Peer sampling is a process that after all the columns are disseminated through the network, you request a column from your peer that’s supposed to have it. If you get the column back, it means that column is available. If not, you may either request another peer or decide that the column is not available.
You can see that you always request for a column no matter what which is different from this proposal. In this proposal, you will request a column only if your peer notifies you that it has one. So peer sampling and this proposal are fundamentally different.
Another difference is, in peer sampling, you aren’t sure when to request a column. In other words, you don’t know when the column dissemination is finished so that you can start requesting the column. What you can do is to set an exact timestamp that you will assume the dissemination is already finished and start requesting. This sometimes waste you some time since the dissemination is finished far before the timestamp. In this proposal, you don’t get this problem since you’re notified when you can request.