
What
ULTRA TX is a way to achieve programmable L1 blocks, unlocking capabilities well beyond what is possible using standard L1 transactions in an L1 block. You could say ULTRA TX is to blocks what account abstraction is to EOAs.
This post will focus on what this means for L2s and the interoperability between L1 and L2s. Other possible use cases will not be explored here.
When you combine the L1 meta tx bundler and the (based) rollup block builders, you have an entity we’ll call the master builder. The master builder will build L1 blocks containing just a single extremely powerful and fat L1 transaction. This single transaction will henceforth be referred to as the ULTRA TX.
This setup makes it efficient and straightforward to do composability and aggregation for L2s and the L1.
For easy L1 composability, the ULTRA TX should be at the top of the L1 block so that the latest L1 state is directly available.
This approach requires no changes to L1.
Why
- Enforcing things across transactions is a nightmare and often simply impossible.
- Doing L1 → L2 (like deposits) with EOA transactions is very inconvenient, especially for synchronous composability. See below why.
- All (or almost all) L1 transactions will be account abstraction transactions. EOA transactions are limited and should gradually go away. Not just for the UX improvements but also for efficiency. Having a smart contract based account with EIP-7702 is now also just a signature away, so easy for users to opt in.
- L2s want to propose/settle together (to share blobs and proof aggregation) and frequently (each L1 block ideally) for efficiency and UX.
- A more extendable L1 paves the way for better UX
- One account abstraction tx bundler on L1 is the most efficient.
- One block builder for all (based) rollups is the most powerful.
For these reasons I believe we are moving towards a future where almost everything will be done by a single L1 transaction. ULTRA TX can be adopted gradually, the rest of the block can be built in the traditional way.
Together with real time proving (in some reasonable capacity), this can achieve the ideal future where Ethereum truly feels like a single chain, where L1 and all L2s can call into each other, and every L2 can (but does not need to) settle in each L1 block, generally without loss in efficiency.
Going forward, Gwyneth will often be referenced to make things more concrete on how things could actually work. This is simply because it is the one I am most familiar with.
Advantages
- Seamless and simple aggregation and interaction between L1 and L2s: L1 and L2 transactions can be used to build blocks in practically the same way with a shared mempool. This removes complexity and efficiency considerations of having to handle L1 transactions differently. See below how this can be achieved.
- Shared data compression and data aggregation into blobs: All rollup data can be shared and stored in blobs together.
- Atomicity: There can now be programmable logic to enforce things across transactions. All logic can be implemented using smart contracts.
- Provability: The whole ULTRA TX can easily be proven because all the inputs are directly available. Anything happening within that requires to be proven can depend on it being proven, or the whole ULTRA TX reverts. This is a major improvement compared to normal transactions where you cannot enforce something across transactions.
- Efficiency: Everything that needs to be proven, can be proven with just a single proof. There is no overhead for storing or sending messages. L1 → L2 calls that have a return value are the exception, but these can use relatively cheap transient storage.
- Access to the latest L1 state: The ULTRA TX being at the top of the block is important so that the latest L1 state is directly available in the block header of the previous block. This avoids the difficulties/inefficiencies of getting/ensuring the latest L1 state at some random point in the L1 block (e.g. no need for EIP-7814 to be able to reason across transaction boundaries). Delayed state root calculation like in EIP-7862 should not have much impact because the blocks can still be built immediately after a new L1 block comes in. However, to be able to prove the L1 state the prover will have to have the Merkle proofs against that state root for all used state.
- Preconfirmations: Only top of block L1 “inclusion” preconfs are required for e.g. gateways to be able to provide L1 and L2 execution preconfirmations. It’s possible to check onchain that a transaction is the 1st transaction in a block using a trick: Set the tx gas limit to the block gas limit and check:
block.gaslimit - gasleft() - intrinsic_gas_cost < 21000. This makes it so that even today there is no problem to enforce this requirement on L1. - Customizable security: Dapps/users can easily choose their security level by executing the transaction on L1 or L2. L1 transactions can still execute with full L1 security, the security of these transactions only depends on the validity of the proof when extended functionality is used.
- Gradual adoption: Transactions can still be placed after the ULTRA TX. This allows gradual adoption of this new way of bundling transactions. This can also be used to limit the amount of work that needs to be proven within 12 seconds. As provers get faster and more capable, the ULTRA TX can include more and more transactions. There can also be no ULTRA TX in a block. Or an ULTRA TX only containing L2 transactions. For blocks where the extra work is either not profitable or simply not possible (e.g. the L1 validator has to build its own block), an L1 block can still be built like normal.
Disadvantages
- Real time proving required for synchronous composability with L1: Currently it is not yet possible to prove L1 blocks with zk in < 10 seconds. It’s expected that zk provers will be capable of real time proving in a year or two. Until then, TEEs and things like AVSs are reasonable solutions that let us glimpse into the future.
- Top of block requirement for L1 composability: The top of the block is the most valuable block space, so this requirement could be problematic. However, L1 meta transactions can now also easily be included in the ULTRA TX, so high value L1 transactions can still be included first without any problem (the builder just has to be careful how those state changes impact the following transactions).
The top of block requirement can be removed when the blocks do not need synchronous composability with L1. It can also be removed when just the dependent L1 state is checked onchain to be the latest values (which can then be submitted to L1 builders with revert protection). This does have an impact on efficiency and there are limits on what L1 state can easily be read onchain. - Block builder sophistication increases: To fully take advantage of this system, sophisticated block builders with high hardware requirements are needed. This is generally already true for block builders today, this approach does go quite a bit further with proving requirements and being able to either run L2 nodes, or at least be able to coordinate the building for them, to be competitive.
- EVM equivalence required at all times: It needs to be possible to prove/simulate the L1 transactions on L2 exactly the way they would execute on L1. This imposes the requirement that the whole system needs to update at exactly the same time that Ethereum hard forks. With provers now capable of taking existing execution clients and proving the same code, this is unlikely to be an issue.
- Ethereum ecosystem opt-in: L1 blocks with ULTRA TXs need to be built for most L1 blocks for the L1 interoperability to work reliably for users.
- L1 transaction proving overhead: L1 transactions included in the ULTRA TX also need to be proven. This is something that could be avoided using other approaches, though it also saves on onchain messaging overhead. Assuming 10s if not 100s of L2s will do the majority of transactions, proving the transactions of just 1 extra chain does not seem like a significant overhead compared to the benefits.
- User opt-in for smart contract accounts: This design does not necessarily require users to have a smart contract account on L1, though in practice it may be the only flow that is supported well. If users don’t care about the added benefits, they can still keep using legacy transactions. They may, however, not be treated as 1st-class citizens.
EOA L1 → L2 limitations
Doing L1 → L2 well is hard with EOA transactions. There’s only so much you can do on L1 to achieve this:
- You propose an actual L2 tx as part of the L1 transaction. This in theory can work, but the problem is that it is generally not known that these L1 transactions will end up proposing an L2 transaction without first executing the transaction. This L2 transaction then also somehow has to make it in the L2 block while not being part of the L2 block building process. It can also be problematic when a single preconfer is supposed to have the sole proposing rights.
- If the L1 → L2 call requires a return value, then a proof also needs to be supplied in the transaction. Extra data needs to be supplied that the user has to sign as part of their transaction, and this data may also get outdated before the transaction ends up onchain. This results in bad UX. If there are many L1 → L2 interactions that would also mean many proofs would have to be verified onchain which makes things very inefficient.
- Gwyneth allows L1 work to be initiated on L2. However, it is impossible to do certain operations like transferring ETH out of an account without a real L1 transaction signed by the owner. Account abstraction solves this problem because now all account modifications can actually be supported both using L1 transactions and L2 transactions.
Extending L1
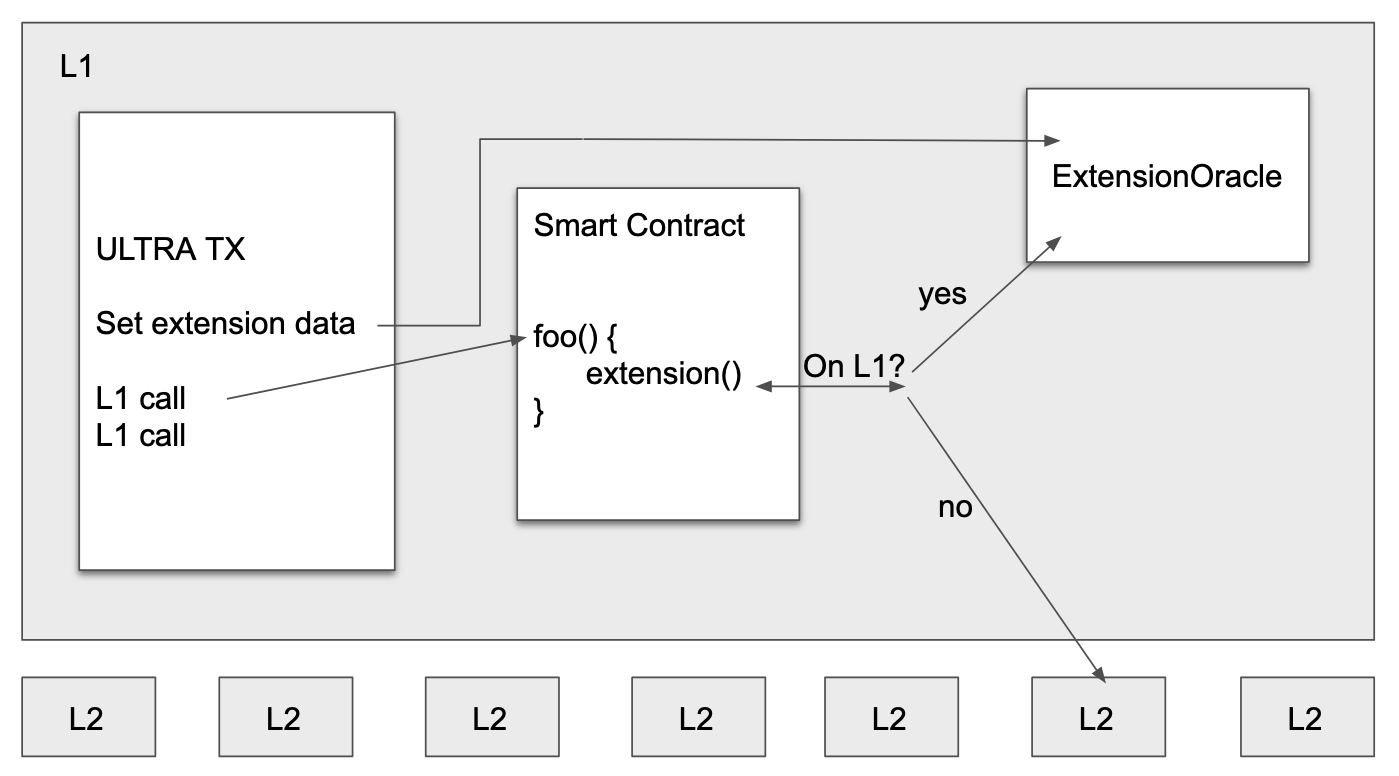
L1 functionality can be extended by putting extra functionality behind an external call (potentially similar to how native rollups will be extendable). In the case of Gwyneth, this call is a cross chain call into L2. When building and proving the block, the block is created as if this extra functionality is also available on L1. The outputs of these calls are collected and sent onchain as part of the ULTRA TX:
- The outputs generated by the extensions called on L1 are stored in the ExtensionOracle contract. These values are set before the call is done as part of the ULTRA TX. The ExtensionOracle is a simple contract that provides the output for each call that is not actually supported by L1. This data is stored in transient storage.
- Now we can actually do the call. Each call to extended functionality checks if the call is supported in the environment it’s currently executing:
- If it’s supported, then the call happens as normal. e.g. the call is actually done to the target contract. This is the path that is followed in the builder/prover.
- If it’s not supported, it means the call instead should be redirected to the ExtensionOracle smart contract where the call output generated offchain will be read instead. This is the path that is followed on L1.
- Finally the proof is verified showing that everything was done as expected.
This extra data is generated and provided by the master builder, not by the user. The user doesn’t have to sign any additional data or verify expensive proofs. The user can interact with smart contracts using extended functionality exactly the same way the user interacts with native functionality.
Developers using the extended functionality in their smart contracts also do not have to know what is actually happening behind the scenes.
Note that this exact approach only works because Gwyneth can “simulate” the execution of L1 transactions to glue everything together. L1 transactions are executed in the prover the same way as they will be on L1 when the ULTRA TX is proposed. This is important to make sure that the correct inputs are used to generate the output.
(Synchronous) Composability
I will again be using Gwyneth’s approach to synchronous composability as an example (you can read up on it quickly here, but also here, here, and here). In short, an additional precompile is added on L2 that allows switching chains for external calls. Gwyneth can also simulate all L1 transactions and afterwards just apply the state updates back to L1.
The assumption I’m going to make here is that each L1 account is a smart contract account and that all L2s are based (such nice assumptions!).
Building blocks can now easily be done as follows:
- We start with the post state for each chain (including for L1). There is no difference between L1 and L2 transactions (except that L1 transactions should be meta transactions, if not they are added to L1 block after the ULTRA TX).
- The L1/L2 transactions are executed in any order the builder wants.
- For L1 transactions, the EVM execution is modified so that the XCALLOPTIONS precompile works exactly the same as on L2 (i.e. it actually executes the call on the target L2) as described above in the Extending L1 section. This allows L1 transactions to call into L2 which is something we need to support for true synchronous composability.
- For any L1 → L2 call, we record the corresponding output of the call.
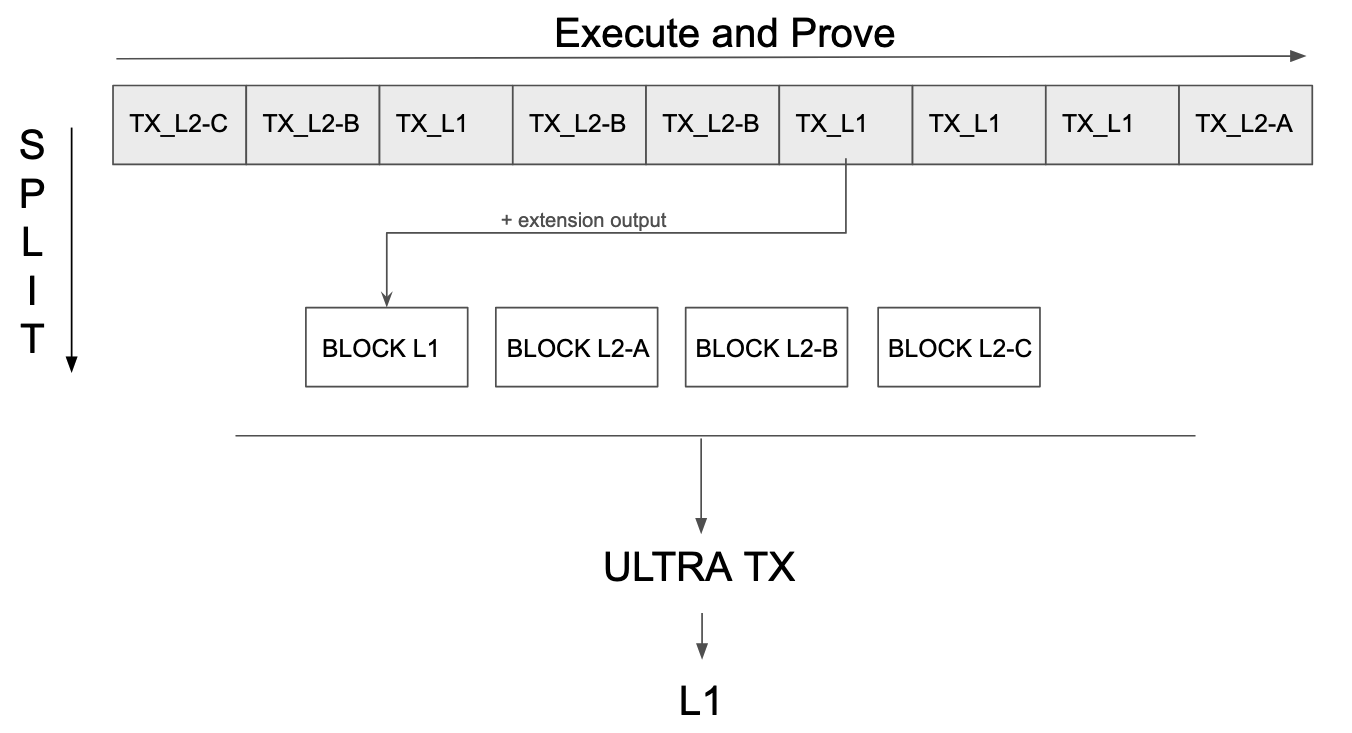
- Once all required transactions are executed locally by the builder, we can seal the blocks:
- For the L2s, either the transactions or the state delta is put on L1 for data availability. This is done for each L2 independently so that they don’t have any interdependencies. The block hashes can be put onchain aggregated to save gas.
- For L1, we need to apply all state changes in the expected order onchain as they happened in the builder. For Gwyneth, this means applying the L1 transactions and the L1 state deltas (for L1 state changes done from L2) in the correct order.
The building process can be repeated as many times as needed to produce any number of blocks. This can be important to support execution preconfs for the transactions that are being included at faster than L1 block times. It is also important to parallelize the block building (see below).
Finally, a single proof is generated of the whole process (note that this may contain sub-proofs, see the section on parallelization below).
The ULTRA TX is then finally proposed onchain. All inputs to the transaction are used as the input to the proof and the proof is verified. If the proof is not valid, the whole transaction reverts.
Note that any additional requirements a builder has to support to be able to correctly include a transaction can be made part of the meta data of the transactions. This way builders can easily see if they are able to include the transaction without having to execute it. These rules can be enforced onchain. For example, for a cross chain transaction the meta tx would contain a list of chains that are allowed to be accessed. If this list is incomplete, the transaction is allowed to revert with the builder getting the transaction fee.
Parallelization
The simplified process above is strictly sequential to allow all chains to interact with each other freely and synchronously in the easiest way. It is possible to build blocks for any set of chains in parallel as well if they do not require synchrony with each other. Multiple blocks can be submitted with practically the same efficiency. This allows breaking the sequential bottleneck and allows achieving greater throughput.
Even if, for example, a chain has an L1 state dependency, it is also still possible to build blocks in parallel. Only the subset of the state used in the block is important to be the actual latest values for the block to be valid.
There can be an additional layer on top of these blocks tracking the global state, while each block only depends directly on this sub state. Each block is proven individually, and then afterwards aggregated together with the additional state checks. The aggregation proof will track the global latest state across blocks and will check that the local state used in the block matches the current latest global state. The builder just has to ensure that these assumptions hold while building the blocks in parallel.
Generalization
The generalization of how this (and more) can be used for all rollups (not just Gwyneth ones) will be coming in part 2. This framework will be called GLUE. A previous sketch was done here. It will contain, in reasonable depth, the interfaces necessary both offchain and onchain to make it possible for all L1 extensions to make use of the proposed design.
Code
Some code to make things more concrete and fun. Some details were omitted for brevity.
What the ULTRA TX would look like onchain:
function proposeBlock(BlockMetadata[] calldata blocks) external payable {
for (uint i = 0; i < blocks.length; i++) {
_proposeBlock(blocks[i]);
}
_prove(blocks);
}
function _proposeBlock(BlockMetadata calldata _block) private {
for (uint i = 0; i < _block.l1Block.transactions.length; i++) {
Transaction calldata _tx = _block.l1Block.transactions[i];
for (uint j = 0; j < _tx.calls.length; j++) {
Call calldata call = _tx.calls[j];
// Set return data in the ExtensionOracle
if (call.returnData.length > 0) {
(bool success, bytes memory result) = address(extensionOracle).call(abi.encode(call.returnData));
require(success == true, "call to extension oracle failed");
}
// L1 account abstraction call
_tx.addr.call{value: call.value}(call.data);
}
// Apply L1 state diff if necessary
if (_tx.slots.length > 0) {
GwynethContract(_tx.addr).applyStateDelta(_tx.slots);
}
}
}
How it looks for developers that want to take advantage of extended functionality:
using EVM for address;
function xTransfer(uint256 fromChain, uint256 toChain, address to, uint256 value) public returns (uint256) {
return on(fromChain)._xTransfer(msg.sender, toChain, to, value);
}
function ChainAddress(uint256 chainId, xERC20 contractAddr) internal view returns (xERC20) {
return xERC20(address(contractAddr).onChain(chainId));
}
function on(uint256 chainId) internal view returns (xERC20) {
return ChainAddress(chainId, this);
}
How extensions can be exposed to developers:
library EVM {
function xCallOptions(uint chainID) public view returns (bool) {
// Call the custom precompile
bytes memory input = abi.encodePacked(version, chainID);
(bool success, bytes memory result) = xCallOptionsAddress.staticcall(input);
return success && bytes4(result) == xCallOptionsMagic;
}
function onChain(address addr, uint chainID) internal view returns (address) {
bool xCallOptionsAvailable = xCallOptions(chainID, false);
if (xCallOptionsAvailable) {
return addr;
} else {
return extensionOracle;
}
}
}
What the Extension Oracle looks like:
contract ExtensionOracle {
uint private transient returndataCounter;
ReturnData[] private transient returndata;
fallback() external payable {
_returnData();
}
receive() external payable {
_returnData();
}
function _returnData() internal {
if (msg.sender == gwyneth) {
returndata = abi.decode(msg.data, (GwynethData.ReturnData[]));
} else {
require(returndataCounter < returndata.length, "invalid call pattern");
ReturnData memory returnData = returndata[returndataCounter++];
bytes memory data = returnData.data;
if (returnData.isRevert) {
assembly {
revert(add(data, 32), mload(data))
}
} else {
assembly {
return(add(data, 32), mload(data))
}
}
}
}
}