Summary & TL;DR
The ProbeLab team (probelab.io ) is carrying out a study on the performance of Gossipsub in Ethereum’s P2P network. Following from our previous post on the Number Duplicate Messages in Ethereum's Gossipsub Network, in this post we investigate bandwidth consumption at the GossipSub level, i.e., bandwidth consumption for message propagation. The target of the study is to identify the protocol components that consume the biggest share of network bandwidth. The study has been co-authored by @cortze and @yiannisbot.
For the purposes of this study, we have built a tool called Hermes, which acts as a GossipSub listener and tracer (GitHub - probe-lab/hermes: A Gossipsub listener and tracer. ). Hermes subscribes to all relevant pubsub topics and traces all protocol interactions. The results reported here are from a 3.5hr trace.
Study Description: The distributed nature of p2p systems makes them generally less effective in computational, latency, and bandwidth consumption. This is due to the extra interactions between nodes needed to organize a p2p network without a central authority that bridges between peers. Thus, taking care of processes, such as peer or content discovery, content sharing, and message broadcasting often become a challenge, or bottleneck.
Ethereum is not different in that respect. Message propagation takes a large portion of the network bandwidth used by a node in the Ethereum network. This study investigates bandwidth consumption at the GossipSub level. The target is to identify the protocol components that consume the biggest share of network bandwidth.
TL;DR: Despite the fact that the configuration of our Hermes node, which, in this case, doesn’t represent a standard node in the Ethereum network, the bandwidth consumption numbers of GossipSub validate that there’s plenty of space for optimization.
We observed that a significant portion of bandwidth is spent on SENT_IHAVE messages (23.4% of the total bandwidth and 30% of the total outgoing bandwidth) and RECV_IHAVE messages (10% of the total bandwidth, and 42% of the total inbound bandwidth).
More than anything, these findings validate the improvement recommendations made during our previous study on the “Effectiveness of Gossipsub’s gossip mechanism”: Gossip IWANT/IHAVE Effectiveness in Ethereum's Gossipsusb network
Taking into account that a node doesn’t only receive duplicated messages but also generates duplicates to others, we strongly recommend pushing the GossipSub1.2 initiative, as it will effectively eliminate the bandwidth wasted on receiving or generating duplicates, which amounts to ~42% of total bandwidth.
Results on Bandwidth Consumption
NOTES: The bandwidth usage displayed in this study is limited to:
- The
Holeskynetwork- The GossipSub RPC calls
- The following GossipSub topics:
beacon_blockbeacon_aggregate_and_proofsync_commmittee_contribution_and_proofattester_slashingproposer_slashingvoluntary_exit* (checkHermesissue → Broadcasting of invalid `voluntary_exit` messages to mesh peers · Issue #24 · probe-lab/hermes · GitHub)bls_to_execution_change- The bandwidth of
SENT_IHAVEandRECV_IHAVERPC calls has been calculated based on the number of bytes pertopicstrings andmsg_idsthat were inside.
NetIn vs NetOut
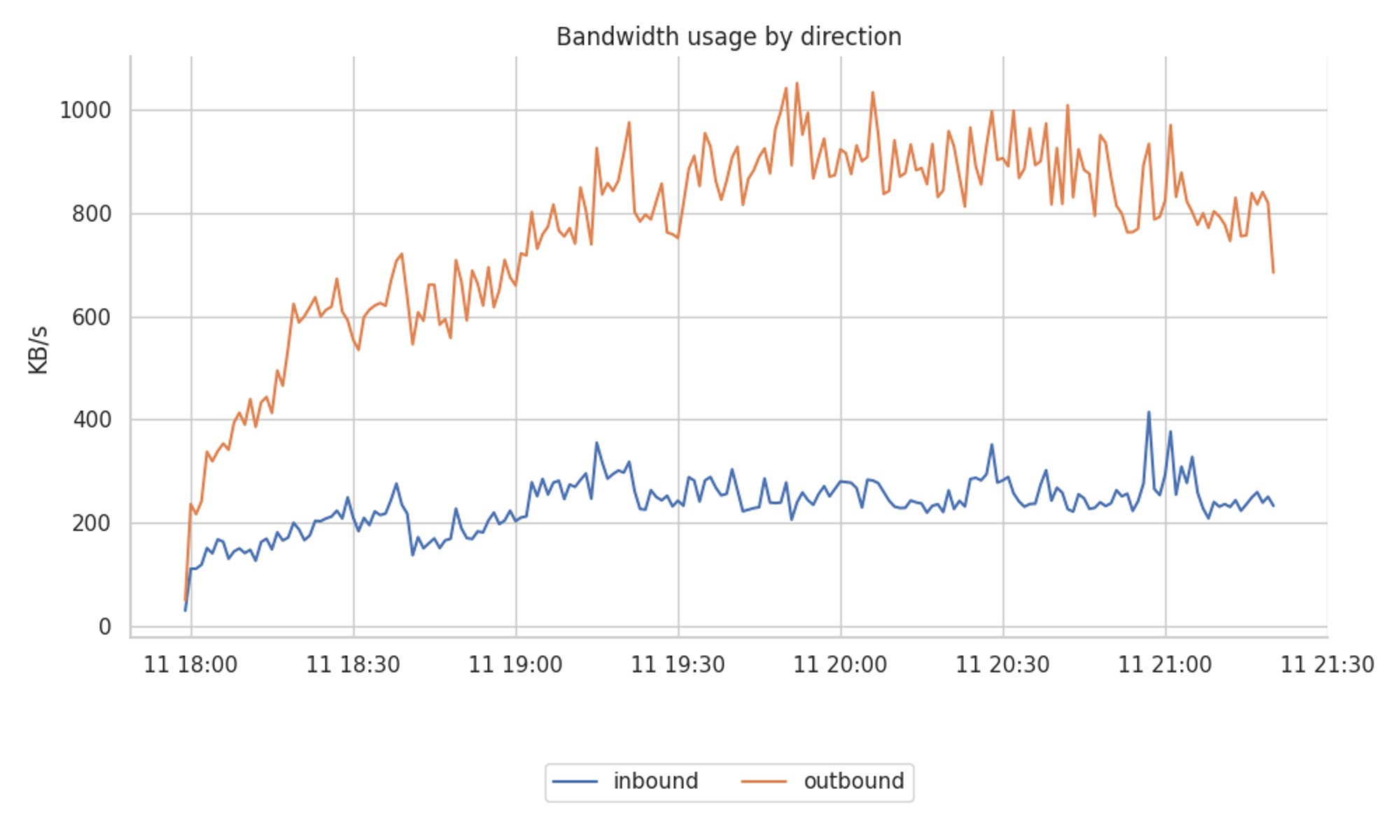
The study starts with a general overview of what is the ratio of sent vs received bandwidth consumption. The following graph shows that on the Hermes node, the biggest share of the bandwidth comes from the data that we send out to the connected peers.
The total outbound bandwidth is around 3 to 4 times higher than the inbound. Note that Hermes differs from a standard node in that it keeps more peer connections (around 250 peers). This clearly has a significant impact on bandwidth usage. That said, although the numbers are not representative of the bandwidth usage of a normal node in absolute terms, the percentage split still represents that of a normal node.
Narrowing down, we observe a ratio of 700-800 KB/s for outgoing traffic and 200 KB/s for incoming traffic.
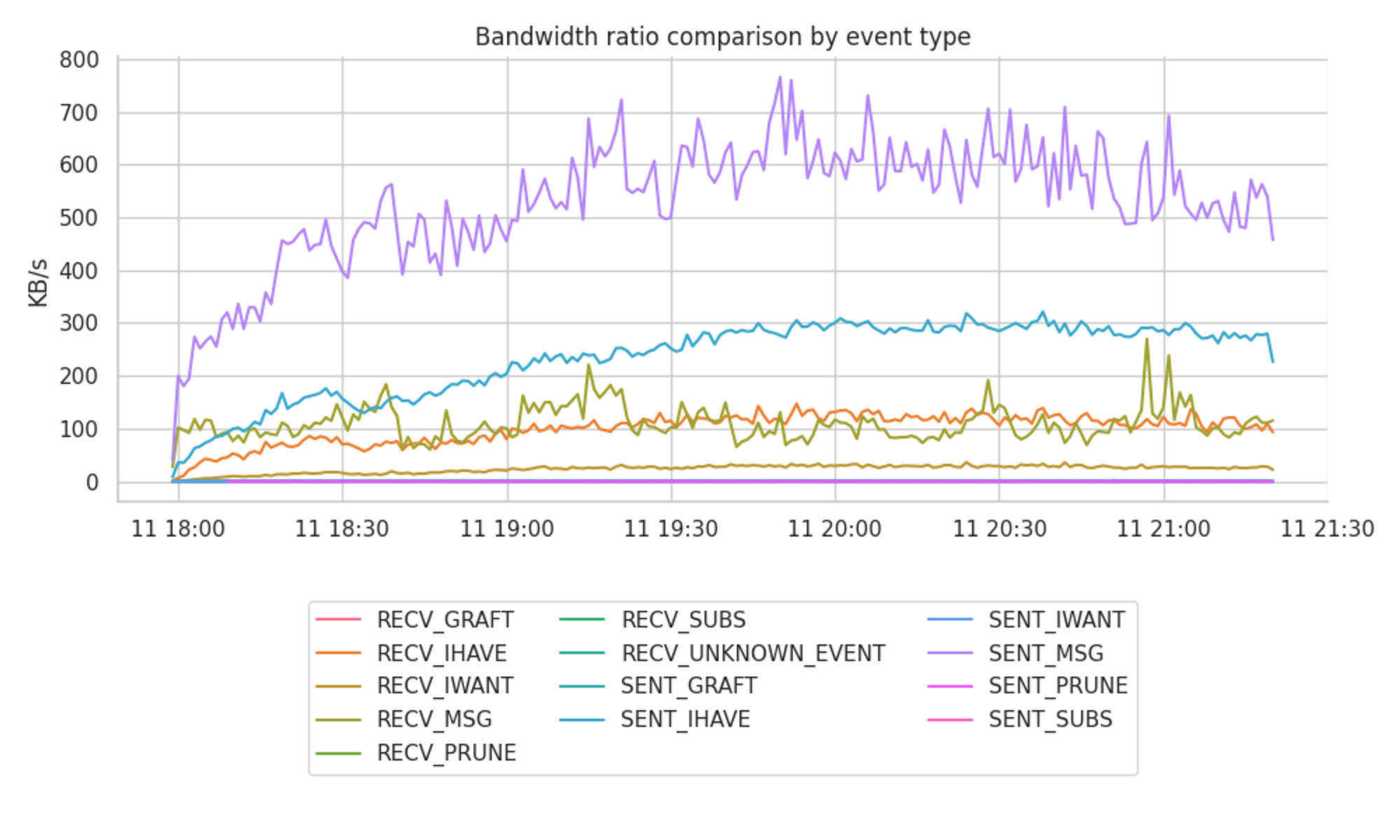
Bandwidth based on each event type
GossipSub sends multiple types of messages with different purposes. From control messages to keep the mesh stable to pure messages or gossip IHAVE / IWANT messages to ensure that the host didn’t miss any message. Each of these message types requires sending RPC calls, adding up to the total of sent and received network traffic.
The following graphs isolate the bandwidth attributed to each of the events. The first one shows the raw KB/s over time, and the second one shows the percentage of each event over the aggregated total.
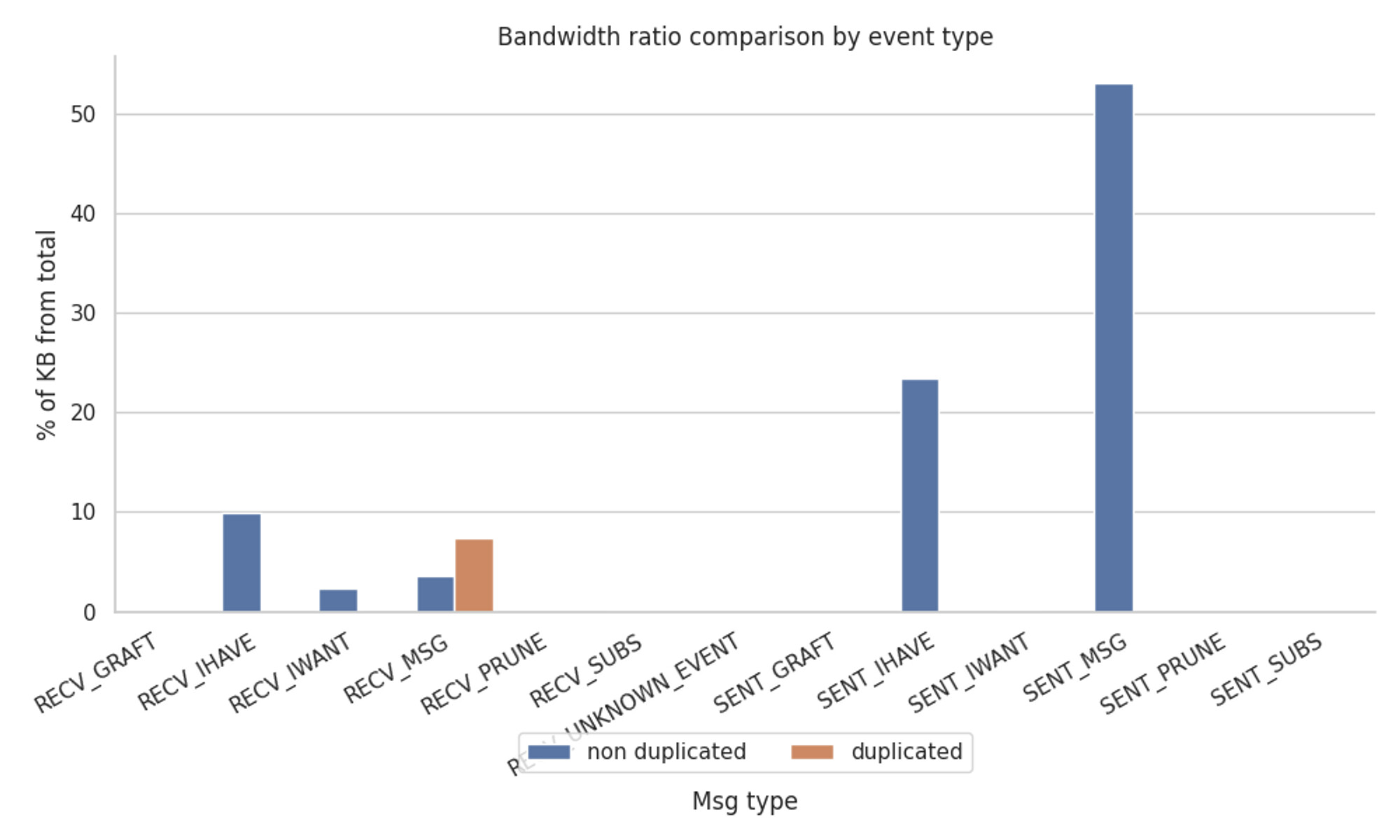
Percentage Table
| Event | % of total BW | % of Received BW | % of Sent BW |
| --- | --- | --- | --- |
| RECV_GRAFT | 0.000367 | 0.001565 | ———————— |
| RECV_IHAVE | 9.974349 | 42.537746 | ———————— |
| RECV_IWANT | 2.368042 | 10.099021 | ———————— |
| RECV_MSG (duplicated) | 7.347250 | 31.333920 | ———————— |
| RECV_MSG | 3.640691 | 15.526507 | ———————— |
| RECV_PRUNE | 0.002973 | 0.012678 | ———————— |
| RECV_SUBS | 0.114559 | 0.488562 | ———————— |
| SENT_GRAFT | 0.002863 | ———————— | 0.003740 |
| SENT_IHAVE | 23.404913 | ———————— | 30.573967 |
| SENT_IWANT | 0.094569 | ———————— | 0.123536 |
| SENT_MSG | 53.049257 | ———————— | 69.298539 |
| SENT_PRUNE | 0.000164 | ———————— | 0.000214 |
| SENT_SUBS | 0.000003 | ———————— | 0.000004 |
From the above graphs, we can observe that:
- The
SENT_MSGevent is the one that consumes the most network traffic, with a total of 53% of the total network traffic and 69% of the total sent traffic.
It has a spiky oscillation between 500 to 700 KB/s, and it is clearly the most bandwidth consuming event.
It is hard to define which is the ratio of duplicates that all those sent messages generate on the remote side. However, we could assume that it would follow a similar pattern to theRECV_MSGone (2 duplicate bytes per 1 original byte). - Surprisingly, the
SENT_IHAVEevent followsSENT_MSGs in terms of consumed bandwidth with a total of 23.4% of the total bandwidth and 30% of the total outgoing bandwidth. Interestingly, subscribing to topics with a high frequency of messages (even if they are small in size), does have an impact on the bandwidth that we use sending thoseIHAVEmessages.
EachIHAVEis limited to5,000message IDs; however, with a message ID of 40 bytes, it still adds up to a maximum of 200KBs in message IDs on every heartbeat (0.7s in the case of Ethereum). RECV_IHAVESrepresent 10% of the total bandwidth, and 42% of the total inbound bandwidth, with an inbound network bandwidth requirement of 100KB/s.- The above two points showcase that, far from being negligible on the overall value they provide, the total bandwidth used on
IHAVEmessages represents almost 400KB/s, consuming 23% of the total outgoing bandwidth and more than 40% of the incoming bandwidth. - The
RECV_MSGevents remain in the fourth position with a representation of 11% of the total consumed bandwidth, where only 3.6% belong to unique or original messages, and the remaining 7.3% belong to duplicates. In terms of the overall inbound bandwidth, they represent 15% and 31%, respectively, for original and duplicated received messages. - On a much lower ratio, the whole list of
RECV_IWANTmessages stays within a lower 2.3% of the total bandwidth usage, which represents 10% of the total received bytes.
Comparison with live nodes
In order to validate the previous measurements taken from the GossipSub module at Hermes, we’ve compared the bandwidth usage ratios with standard running Ethereum nodes:
- Local Prysm node at home setup (Holesky) reports an average received network traffic of 386KB/s and a sent network traffic of 580KB/s.
Although the numbers might be slightly different, these measurements take the whole traffic of the Beacon Node docker container, which includes:- Peer discovery
- Requests/Responses like
beacon_blocsorblobsby range or by root
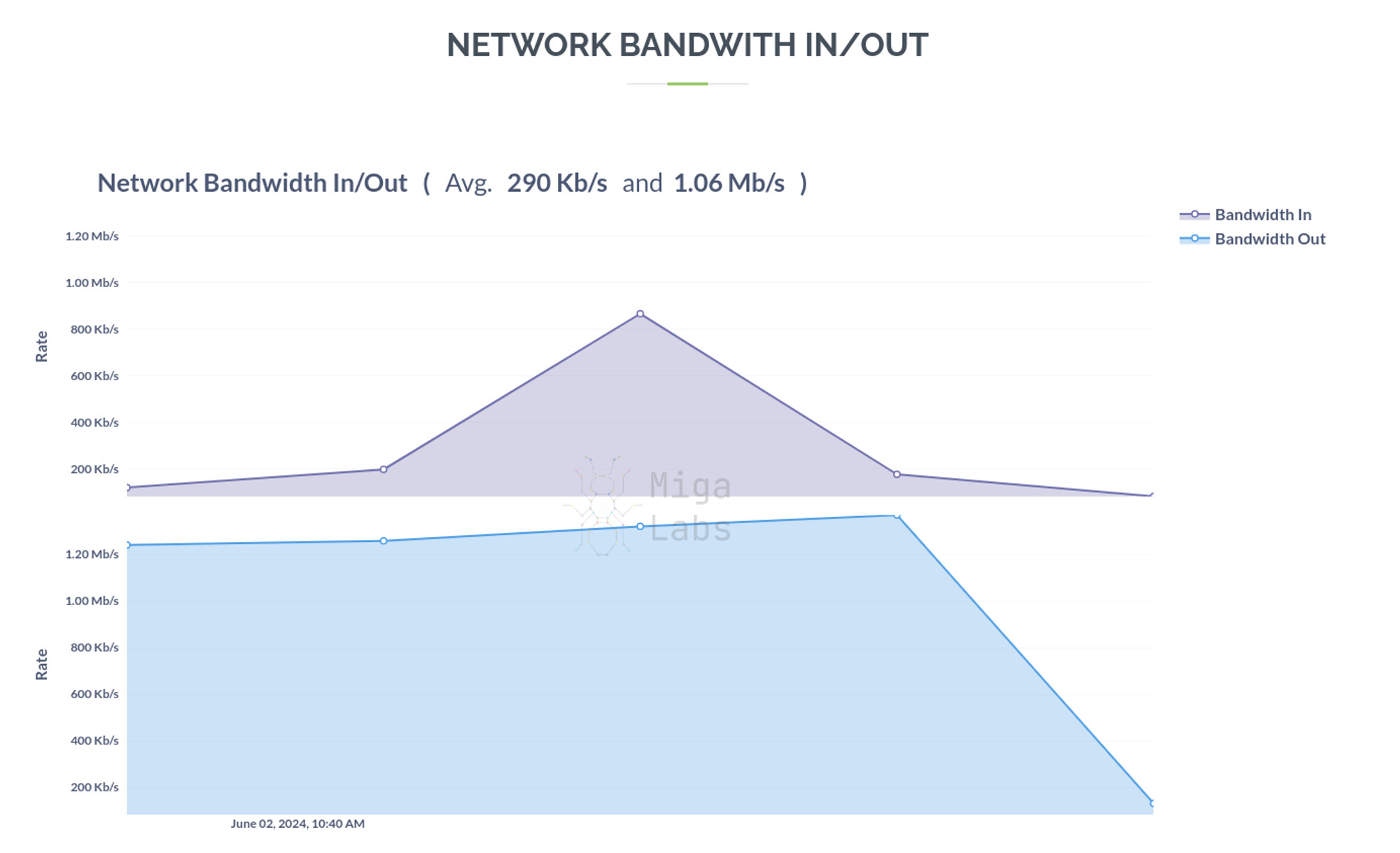
The MigaLabs public dashboard at monitor.eth shows slightly bigger bandwidth usage than the ones we measured. However, it is unclear whether the measurement includes the Execution Layer. The reported bandwidth reports an average of 290KB/s inbound and 1.2MB/s outbound, although it doesn’t include many data points (5 points per hour) and the variation is noticeable.
Conclusions and takeaways
Despite the fact that the configuration of our Hermes node, which, in this case, doesn’t represent a standard node in the Ethereum network, the bandwidth consumption numbers of GossipSub validate that there’s plenty of space for optimization.
We observed that a significant portion of bandwidth is spent on SENT_IHAVE (23.4% of the total bandwidth and 30% of the total outgoing bandwidth) and RECV_IHAVE (10% of the total bandwidth, and 42% of the total inbound bandwidth).
More than anything, these findings validate the improvement recommendations made during our previous study on the “Effectiveness of Gossipsub’s gossip mechanism”: Gossip IWANT/IHAVE Effectiveness in Ethereum's Gossipsusb network
Taking into account that a node doesn’t only receive duplicated messages but also generates duplicates to others, we strongly recommend pushing the GossipSub1.2 initiative, as it will effectively eliminate the bandwidth wasted on receiving or generating duplicates, which amounts to ~42% of total bandwidth.
Even currently though, the network bandwidth usage of a host in the Ethereum network (around 300 KB/s inbound and 1.1 MB/s outbound, including the EL) still constitutes a small percentage of the average household bandwidth availability, which varies between 8MB/s and 26MB/s depending on the region.
For more details and weekly network health reports on Ethereum’s discv5 DHT network head over to probelab.io.