Author: Luca Zanolini
Huge thanks to Ben, Francesco, Joachim, Justin, Mikhail, Roberto, Thomas, Vitalik, and Yann for their feedback.
We are working on a proposal for the next consensus protocol for Ethereum. A central piece of the new design is a two-layer architecture: a fast available chain — the heartbeat — produced by a small randomly-sampled committee, and a separate finality mechanism that trails behind, finalizing blocks the heartbeat has already produced — crucially, with the two layers fully decoupled, unlike the current Gasper design where LMD-GHOST and Casper FFG interact in ways that have proven difficult to reason about. Vitalik outlined this direction in a recent post.
This post focuses on the first layer — the heartbeat — and on a property we believe should be a strict requirement for it: dynamic availability.
Why dynamic availability matters
Ethereum has never gone offline[1]. Through the Merge, through client bugs, through cloud provider outages — the chain has kept producing blocks. This is not an accident. It is a consequence of how the protocol handles fluctuating participation, and it is a property the next consensus design should strengthen, not compromise.
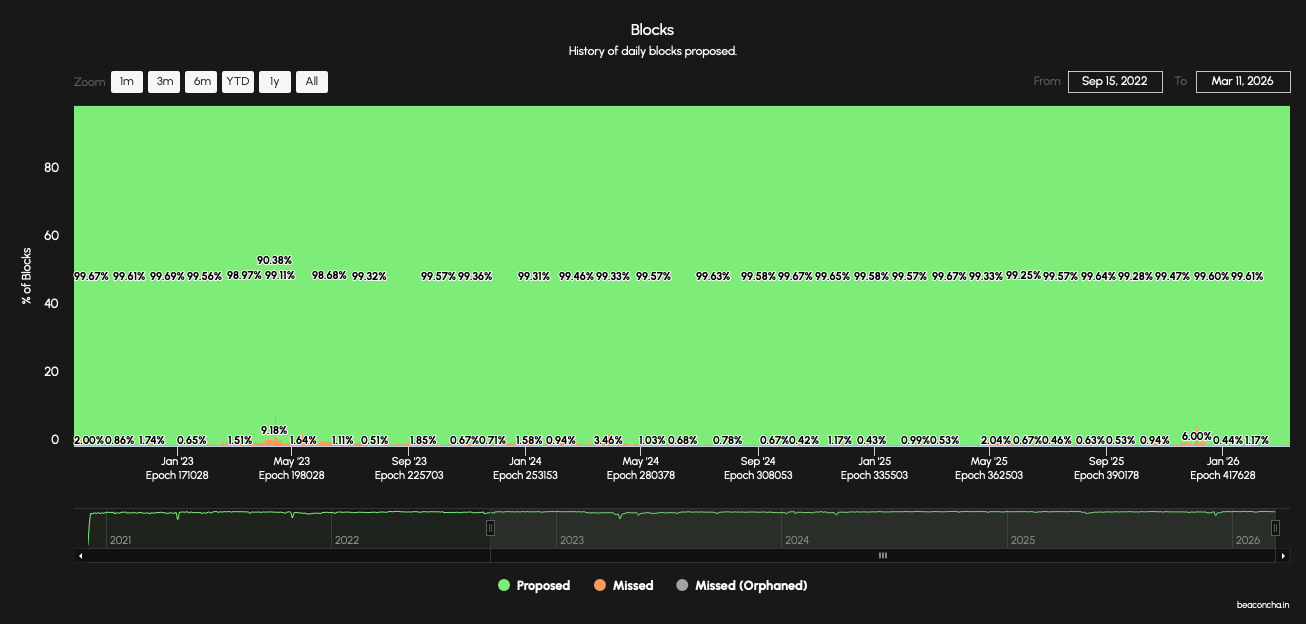
Figure 1. History of daily block proposals on the Ethereum Beacon Chain (source). Green represents slots in which a block was proposed, orange represents missed slots, grey represents orphaned blocks. The lowest recorded proposal rate was ~90% during the May 2023 consensus client incident. The rate has never approached zero.
Dynamic availability is the formalization of this property: a protocol is dynamically available if it remains safe and live as long as a majority of the currently awake[2] stake is honest. Not a majority of all registered validators — a majority of the awake ones. The chain keeps going regardless of how many validators are asleep, as long as the ones that are awake are mostly honest.
Why should this be a strict requirement?
Resilience and self-recovery. When validators go offline — due to a consensus client bug, a cloud provider outage, or a regional network disruption — a dynamically available protocol continues producing blocks. In the common case, recovery is straightforward: the affected operators fix the bug, the data center comes back online, and participation returns to normal. The chain never stopped, so there is nothing to restart. If participation does not recover — if a large fraction of validators remains offline indefinitely — Ethereum has a fallback: the inactivity leak, a mechanism that gradually penalizes inactive validators, reducing their effective stake until the finality gadget can resume operation, without out-of-band coordination. There is a class of chains — typically optimized for throughput — that implicitly rely on a responsive social layer for recovery from extreme events: the chain halts, a small group of stakeholders gets on a call to coordinate, and validators restart in unison. When decentralization is not the primary constraint, this approach is efficient. It is not compatible with Ethereum’s design philosophy.
These are not hypothetical scenarios. In May 2023, bugs in the Prysm and Teku consensus clients (together running over 50% of validators) caused Ethereum’s first mainnet inactivity leak. In November 2020, a consensus bug in Geth caused a small portion of the network to split off, disrupting services that relied on affected nodes, including Infura, MetaMask, MakerDAO, and Uniswap. When a majority client forks, dynamic availability ensures both forks continue to operate. Individual operators can identify and switch to the correct fork well before network-wide convergence.
Censorship resistance. If an adversary with majority stake begins censoring, the honest minority needs to mount a response. A dynamically available chain allows them to begin building an alternative fork, even with a small number of validators, and grow it as others recognize the situation and join.
Application-layer continuity. DeFi protocols, rollups, and bridges all depend on a functioning L1. A halted base layer freezes composable DeFi simultaneously (liquidations cannot execute, oracle prices become stale, positions accumulate unmanageable risk), stalls rollup operations (batch posting, fraud proofs, validity proofs), and forces bridges into ambiguous states. This is not theoretical: during Solana’s February 2024 halt, the chain stopped producing blocks for five hours — DeFi protocols were completely inoperable, positions could not be adjusted, and risk accumulated with no mechanism to manage it. By contrast, during Ethereum’s May 2023 finality disruption, blocks kept being produced and transactions continued to process normally — the application layer was largely unaffected because the available chain never stopped. Final settlement still requires the finality layer, but operational continuity depends on the heartbeat continuing to produce blocks.
There is a unifying principle behind these points:
it’s better to give people as much information about the future state of the chain as possible.
This is the same principle that makes shorter finality times preferable to longer ones, and finality preferable to purely probabilistic confirmation. When finality is interrupted, a dynamically available chain provides partial but useful information about the likely future state. A halted chain provides none.
The world BFT assumes is not the world Ethereum lives in
Most consensus protocols you’ve heard of — PBFT, Tendermint, HotStuff — assume a fixed set of validators that are reliably awake. Under that model, safety is provable, but liveness typically fails if too many validators go offline (often around \ge \frac{1}{3}). That tradeoff is unavoidable.
Ethereum has thousands of independently operated nodes, and even well-incentivized operators go offline: upgrades, cloud and ISP incidents, hardware failures, misconfigurations, ordinary human error. Designing a protocol that needs “near-perfect participation” for liveness is designing for a world that doesn’t exist.
The sleepy model takes (some aspects of) the real world seriously: honest validators can be awake or asleep, and that can change over time. In this setting, a protocol is dynamically available if it remains safe and live as long as a majority of the currently awake stake is honest. Sleeping validators are not counted against any fault budget — neither Byzantine nor crash. This matters in practice: real-world outages have pushed participation down to around 33% (Figure 10), a level that would exceed the fault tolerance of any protocol that accounts for offline validators as faulty.
Put differently:
Ethereum should keep producing a coherent chain as long as most of the stake that is actually awake is honest.
You cannot avoid the two-layer split
One might ask: why not build a single protocol that is both dynamically available and provides finality? Put differently: why do we need a trailing finality mechanism on top? The answer is that this is impossible.
The availability-finality dilemma — a blockchain-specific form of the CAP theorem — proves that no single protocol can guarantee both:
- Liveness under dynamic participation: the chain continues to grow even as the set of awake validators fluctuates.
- Safety under network partitions: once a transaction is confirmed, it cannot be reverted even if the network temporarily splits.
In other terms, dynamically available protocols must assume synchrony.
BFT protocols achieve partition safety but halt when participation drops. Longest-chain protocols, e.g., Bitcoin’s consensus protocol, achieve dynamic availability but offer only probabilistic confirmation — and must assume synchrony to do so. No protocol can do both at once. This is a fundamental limitation.
The architectural implication is direct: any protocol that aims to never halt and to provide irreversible finality must have a dynamically available component. The heartbeat layer is not an optimization — it is a structural necessity imposed by the impossibility result.
From property to protocol
Saying the heartbeat must be dynamically available still leaves open what protocol to use. The requirement rules out off-the-shelf BFT (which halts under dynamic participation), but it also rules out naive adaptations of LMD-GHOST. While Gasper functions well in practice under varying participation levels, LMD-GHOST cannot be proven dynamically available: Neu, Tas, and Tse demonstrated adversarial strategies that violate safety and liveness of LMD-GHOST in the synchronous model, and subsequent patches have not closed the gap. A protocol is dynamically available by definition only if it satisfies both safety and liveness in the sleepy model — the existence of these attacks means LMD-GHOST does not meet this bar.
Goldfish was designed to close this gap. It is a propose-and-vote protocol — structurally closer to BFT than to longest chain — that achieves dynamic availability with:
- Constant expected confirmation latency: the time to confirm does not grow with the target security level. This is the key separation from longest-chain protocols.
- Reorg resilience: blocks proposed by honest proposers are guaranteed to remain in the canonical chain. This property, absent in LMD-GHOST, eliminates a class of attacks that have plagued Ethereum’s current fork-choice rule.
- Subsampling: the protocol can run with a randomly selected committee of ~256 validators per slot, keeping per-slot communication O(1) relative to the total validator set.
- Composability: Goldfish can serve as the available-chain component in an ebb-and-flow protocol, pairing with a finality gadget.
What this buys in practice: slot times
The current Ethereum slot structure requires aggregating ~30,000 attestations per slot. If Ethereum moves to single-slot epochs, this number rises by default to the full active validator set — currently around one million. Any future reduction of the 32 ETH deposit minimum would push it even higher. Because these numbers far exceed what a single subnet can propagate, attestations pass through multiple aggregation rounds before reaching the global network. As Vitalik observes:
\text{aggregation time} \approx \log_C(\text{validator count})
where C is the per-subnet capacity (hundreds to low thousands of signatures), and the aggregation time is measured in network rounds, each taking roughly \Delta[3]. With the full validator set on the critical path, each slot requires between 3\Delta and 4\Delta.
A dynamically available protocol with ~256 subsampled validators fits within a single subnet broadcast. No aggregation rounds are needed. This removes the aggregation overhead entirely, leaving only the time for block propagation and committee voting on the critical path.[4]
Finality still involves the full validator set, but it proceeds in parallel with the dynamically available component, off the critical path. The two layers do not compete for the same latency budget.
A near-term benefit: post-quantum readiness and post-quantum heartbeat
The transition to post-quantum cryptography is an ongoing concern for Ethereum. A major obstacle is signature aggregation: Ethereum currently relies on BLS signatures, which can be efficiently and easily aggregated, but no post-quantum signature scheme offers comparable aggregation properties at practical sizes.
A dynamically available heartbeat with a small subsampled committee sidesteps this problem. With ~256 validators per slot, signatures do not need to be aggregated at all — they can be naively concatenated. Post-quantum signature sizes vary by scheme; with a scheme at ~3 KB per signature, 256 signatures amount to ~768 KB. leanMultisig — a minimal zkVM targeting XMSS signature aggregation and recursion — can compress this further: early benchmarks show aggregation of over a thousand signatures with proof sizes in the 300–500 KB range, approaching the cost of naive concatenation. These results currently rely on a conjectured security assumption; provably secure parameters are in progress.
This means a post-quantum heartbeat — a dynamically available protocol running with post-quantum signatures — could be deployed significantly sooner than a full post-quantum decoupled protocol, which would additionally require post-quantum signature aggregation for the finality layer’s full validator set. The heartbeat-finality decoupling makes this incremental deployment path possible: upgrade the heartbeat to post-quantum first, address finality-layer signatures separately as post-quantum aggregation techniques mature.
Without this decoupling, post-quantum migration becomes an all-or-nothing problem: you cannot upgrade Ethereum’s signatures until you have a PQ aggregation scheme that scales to the full validator set — an active area of research. The two-layer architecture turns this into two independent problems, one of which (~256 concatenated signatures) is solvable with existing schemes today.
What we are building
The target architecture:
- Heartbeat: a dynamically available protocol (Goldfish/RLMD-GHOST family) with ~256 randomly sampled validators per slot — small enough to operate with concatenated post-quantum signatures, enabling a post-quantum heartbeat as an early deployment milestone.
- Trailing finality gadget: a separate mechanism using the full active validator set, finalizing the heartbeat’s chain head.
The two layers are fully decoupled. This yields fast slots, flexibility in choosing the finality mechanism, a clean separation during inactivity leaks, and reduced complexity relative to Gasper.
A detailed treatment of the finality layer will follow in a subsequent post.
We refer to block production, not finality. Finality has been temporarily disrupted — most notably during the May 2023 consensus clients incident — but the chain never stopped producing blocks. The daily block proposal chart shows that even during this incident, over 90% of slots received a proposed block. This was a joint consequence of client diversity (Lighthouse, Nimbus, and Lodestar were unaffected by the Prysm/Teku bug) and dynamic availability (the protocol kept producing blocks with the validators that remained awake, rather than halting because total participation fell below an absolute threshold). ↩︎
We use “awake” in the sense of the sleepy model: a validator is awake if it is actively participating in the protocol, and asleep otherwise. This is a protocol-level notion, distinct from network connectivity. ↩︎
\Delta denotes the assumed upper bound on network message delivery time between any two honest validators. ↩︎
The precise slot structure depends on the protocol. Goldfish, for example, uses 3\Delta slots (proposal, vote buffering, voting) or 4\Delta if fast confirmations are implemented. ↩︎