Currently, there are two major types of rollups:
- Based rollups, where the ordering of transactions on the rollup is determined by an L1: a rollup block is an L1 transaction, and the order of the blocks is the same as the order in which those transactions appear on L1.
- Sequenced rollups, where the ordering of transactions is determined by an offchain mechanism, eg. a centralized sequencer or BFT consensus. The rollup hibestory is regularly committed to L1, but ordering decisions are clearly made by the offchain mechanism.
Sequenced rollups have the major advantage that they can offer latency far lower than the Ethereum L1. Based rollups have the major advantage that they can offer synchronous composability with the Ethereum L1. A transaction will be able to perform actions that use both L1 and L2 liquidity, by directly containing an entire L2 block, and taking actions before and after it, including post-assertions that revert everything (including the L2 block), if they fail.
This post will demonstrate that it is possible to combine both, with some limits.
The design
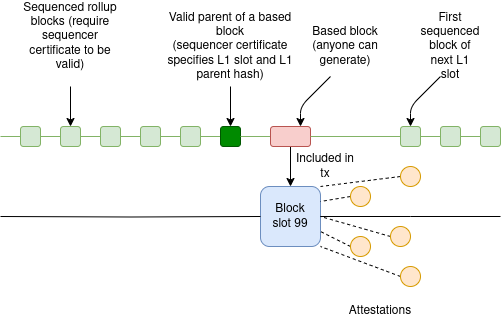
There are three types of L2 blocks:
- Regular sequenced blocks: these require a sequencer certificate (eg. central server signature, votes from 2/3 committee…) to be valid, and they come frequently
- Slot-ending sequenced blocks: these require a sequencer certificate, and come with a special message that it is valid to build a based block on top of them and include it in the L1, only during the current slot (and also if the L1 parent block matches)
- Based blocks: anyone can build them and include them, but only on top of a slot-ending sequenced block (or, potentially, on top of another based block)
The L2 sequencer’s job is to play a timing game. Normally, they release sequenced rollup blocks with very low latency. Then, close to the slot’s end, they release a slot-ending sequenced block - early enough that a builder can make a based block and include it, but late enough that the period of not having very low latency will be minimized. Finally, they start making sequenced blocks for the next slot as soon as they are confident that the L1 block is confirmed.
If, in a given slot, a based block is not included (either because no one shows up to build on time, or because the proposer is missing or defective), then the sequencer starts the next slot by building directly on top of the previous slot’s slot-ending block.
Properties
- This design is only compatible with L2s that are willing to revert if the L1 reverts. This is because if a based block reverts, any sequenced blocks built on top will also revert. Waiting until the L1 block containing the based block finalizes will be an unreasonably long delay, even under theoretically ideal L1 finality mechanisms.
- Under normal circumstances, the delay around the L1 block-publishing time should be pretty short. The L2 publishes its slot-ending block, immediately builders build based blocks on top of it, very soon the proposer makes its L1 block including them, and then attesters make attestations immediately after the proposer proposes, clearing the way for new sequenced blocks to come in.
- Note that there is no security risk in publishing a slot-ending block too late: the worst that happens is simply that no one builds on it. However, there is a security risk in publishing the first sequenced block of the next slot too early, because if the sequencer builds on top of a block that gets reorged, their block will also get reorged.
- The longest delay comes in the case of a missing proposer, because attesters will wait to make sure no proposer is present, and only then publish attestations
- This design does not gain the permissionlessness benefits of based rollups, because building a based block requires the sequencer certificate from a slot-ending sequenced block. To achieve permissionlessness, the easiest path is to introduce a forced-inclusion channel on L1. The based block builders can be responsible for including all transactions in the forced-inclusion inbox.
22 Likes
Love this new take! In a way it feels opposite to the approach of SCOPE. There, a sequenced rollup can synchronously compose with the L1 if it finds someone willing to sell them L1 blockspace (without the rollup being “based”). IIUC here, a sequenced rollup can synchronously compose with the L1 if it finds someone that can supply the composasable transactions. In either case, you don’t need to be a “based” rollup, you just need some coordination with the L1 block building supply chain.
Assuming we’re talking about rollups with validity proofs, some questions/drawbacks around timing:
- Builders cannot credibly offer “based preconfs” until they’ve seen the slot-ending block as prior L2 transactions will change the state on them. This makes it tricky from a UX POV as the composability window is very short so maybe only builders would take advantage of it?
- For atomicity, we need to prove the L2 in real-time, then post the batches + validity proof + L1 sync composable calls all in the same L1 transaction. A concern is that real-time proving is already a feat. If you must wait to start this process until close to the slot’s end then you may have to tradeoff in other dimensions like decreasing gas limits?
2 Likes
The design here is definitely an opposite philosophy to SCOPE, in the sense that it’s assuming L1 builders are “dumb”, and do not offer preconfs, whereas the L2 does offer preconfs. So it’s the approach you want to take if L1 runs on ePBS, which is (at least in its simplest version) incompatible with preconfs.
A concern is that real-time proving is already a feat. If you must wait to start this process until close to the slot’s end then you may have to tradeoff in other dimensions like decreasing gas limits?
I agree that this is definitely a weakness. You would need a streaming prover and to make that technology work well, otherwise your “dead time” before the L1 proposal time becomes longer.
3 Likes
This design does not gain the permissionlessness benefits of based rollups, because building a based block requires the sequencer certificate from a slot-ending sequenced block.
Can you elaborate on this? I understood it as even though it’s permissionless to be a based block publisher, the sequencer can decide never to post slot-ending blocks in the first place → no sync composability.
If that’s the issue, instead of defining the slot-ending slot explicitly via a special sequencer certificate, can it be defined implicitly by the rollup’s rules and checked as a validity condition?
Like for each L1 slot S, the N’th (certified and) sequenced L2 block with l1_slot = S is definitionally the slot-ending block. The sequencer can still prevent the synchronous composability window by publishing < N blocks but at the cost of degraded throughput / reputation / UX / etc.
1 Like
Like for each L1 slot S, the N’th (certified and) sequenced L2 block with l1_slot = S is definitionally the slot-ending block. The sequencer can still prevent the synchronous composability window by publishing < N blocks but at the cost of degraded throughput / reputation / UX / etc.
Yeah I think doing this is reasonable. You can’t prevent the sequencer from stalling (I guess you can have an onchain mechanism that if no new block appeared on L1 for >10 slots, then it automatically enters based mode and any L2 preconfs since the previous based block are then invalidated, ie. equivalent consequences to a short reorg), but you can make it unattractive for them to do that.
2 Likes
This has been said for a couple of years now, and I agree with the theory. But do any existing rollups offer this? And if not, why is that?
Yeah I knew about ULTRA and Gwyneth (wrote a short summary about the latter here). But not sure about the status. I wasn’t aware of Surge, thanks for sharing!
1 Like
And if not, why is that?
L1<>L2 synchronous composability requires a few ingredients that have always been just out of reach until now:
- real-time proving for atomicity: you need to prove the L2’s STF within one L1 slot so that the L2 leg of a synchronously composable transaction can be verified as correct when consumed by L1. In other words, you don’t want the L1 to mint() to succeed if the L2’s burn() reverted.
- reorging with the L1: kind of like the opposite of point 1, you don’t want your L2’s burn() to succeed if the L1’s mint() reorged out.
- coordination between L2 sequencers and L1 proposers: the de facto was a shared, “based” sequencer with a monopoly over both blockspaces. SCOPE showed the sequencer can purchase L1 blockspace and this post shows the sequencer can make the L2 blockspace available to L1 PBS.
Point 1 was always out of reach until recently.
Point 2 is more philosphical for rollup teams to consider (the UX pros of synchronous composability should outweigh the cons of short reorgs).
And for point 3, many teams have been making progress but success hinged on large changes to PBS and major validator buy-in for L1 preconfs before considering rollups changing their stacks. This post shows that there may be a shortcut to skip all of this.
6 Likes
Great idea!
I definitely agree with the vision and its impact to synchronous composability for the Ethereum ecosystem.
I think I actually already pushed for this exact idea, though I called it rebased rollups, about a year and a half ago. I presented rebased rollups right after I met you actually! and as you presented next door at Protocol Berg v2.
Very happy to discuss further ways to make this a reality for Ethereum 
4 Likes
The problem here is that if there is a reorg that misses a base block or includes a different base block then the sequencer will have to recompute a huge reorg that will massively affect its performance.
2 Likes
This is not so much of a problem for a number of reasons:
1- It is up to the sequencer to decide when a based block is due. It doesn’t have to be in every eth block.
2- The sequencer can time the based block so that a few blocks after include transactions that do not conflict with the state of the based block. This means that an L1 reorg only affects the txs in the based block if anything, but otherwise the reorg does not affect the rest of txs fundamentally (they appear in the same relative order in the new branch).
3- Even if a based block reorgs, the new based block will include the same txs with high probability.
1 Like
You can checkout Puffer UniFi, we already have sync composability active on our based rollup testnet instance.
1 Like
I think this is just great! I think this is how you enable innovation, or at least free it up! I think it opens the doors to all kinds of possibilities, the kind I’ve been thinking about nonstop for months!
This is really cool, reminds me a lot of what Kaspa is achieving in vProgs!
@vbuterin Do they have to be blocks? Why not just one continuous stream?