Blob Streaming
By @QED, @fradamt, @Julian with special thanks to @soispoke, @aelowsson and @casparschwa for their valuable input.
We propose blob streaming: enshrining continuous, sampled pre-propagation of blob data as a first-class in-protocol mechanism, alongside the existing critical-path blob lane. Pre-propagation already happens through the blobpool, but with weak guarantees and without data-availability sampling, it cannot be relied on to safely scale throughput. Blob streaming introduces a ticket mechanism to rate-limit pre-propagation, allowing sampling to be reliably extended to the entire slot without extending the critical path — therefore alleviating the free option problem. Beyond scaling, the mechanism also enables full censorship resistance for blob txs.
Introduction
Definition: JIT and AOT blobs
We say that a blob is JIT (just-in-time) if it is propagated in the critical path of the slot that requires its availability. Otherwise, we say that a blob is AOT (ahead-of-time).
Ethereum’s DA machinery was originally designed around JIT blobs, with propagation in the critical path on the Consensus Layer (CL). This machinery has been upgraded via PeerDAS, to enable data-availability sampling. However, the Execution Layer (EL) blobpool has in practice enabled AOT blobs, by providing an avenue for pre-propagation.
Though JIT blobs in principle enable functionality that AOT blobs cannot provide — co-creation of blocks and blobs is necessary for synchronous composability with the L1 — all current blob usage is in practice AOT. The blobpool has therefore allowed work to move out of the critical path, spreading bandwidth use over time. Yet this pre-propagation happens with weak guarantees and without data-availability sampling, so the scaling benefits it can provide are limited.
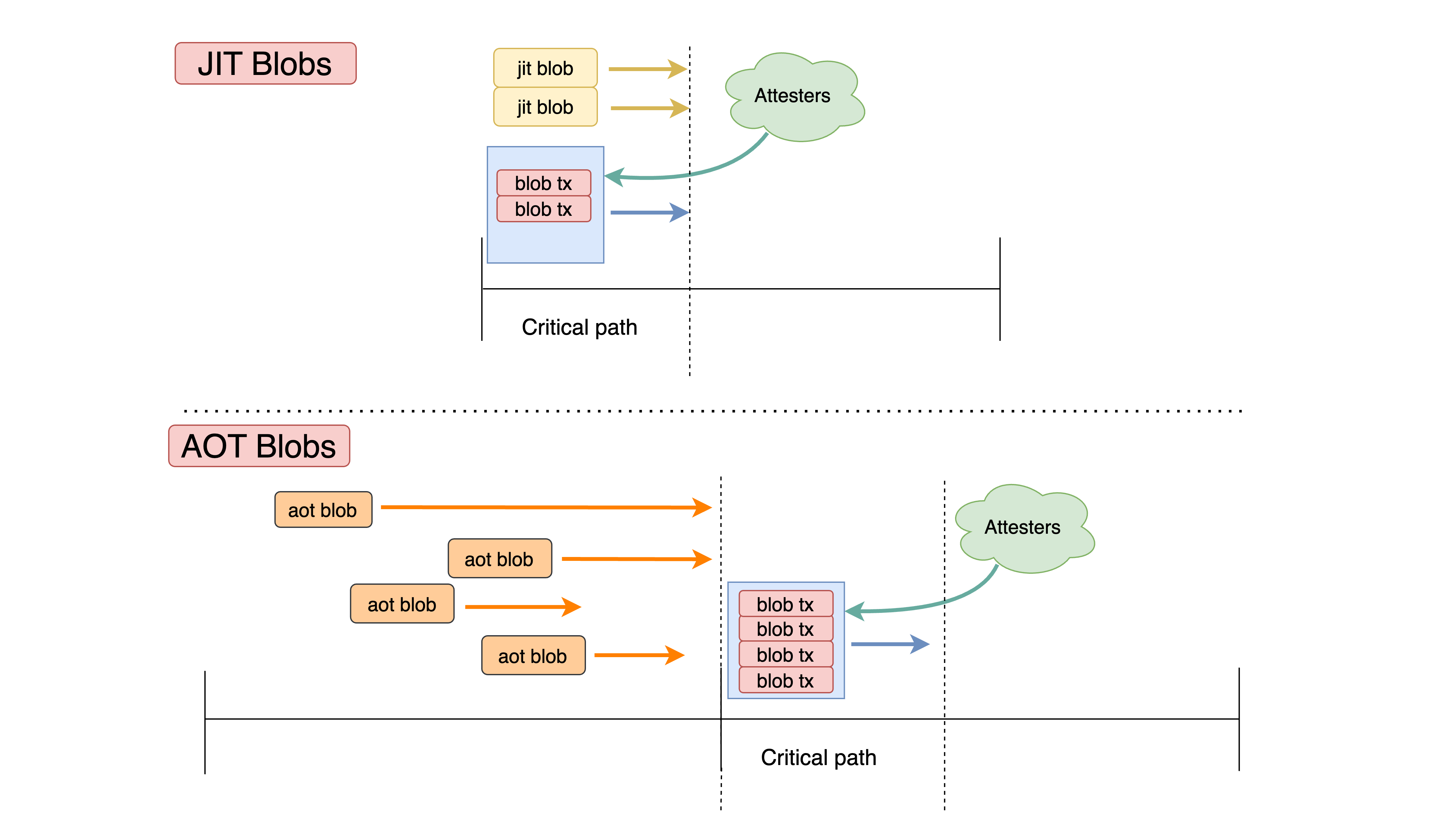
Figure 1. Slot timeline visualizing the JIT/AOT definition. AOT blobs (orange) are propagated before the critical path; JIT blobs (yellow) are propagated within the critical path of the slot requiring their availability. Regardless of when and how propagation has happened, attesters verify availability of all blobs.
In this post, we propose blob streaming: enshrining AOT blobs as a first-class, ticket-based lane — where users purchase the right to propagate a blob ahead of time — alongside a spot-priced JIT lane — which can be thought of as today’s private blobs. The streaming lane is additive: AOT blobs pre-propagate before the critical path while JIT blobs propagate within it. Crucially, ticket-based rate-limiting bounds the propagation load, making pre-propagation inherently reliable — consistent node views, clear DoS resistance. Moreover, because propagation rights are decoupled from availability determination (unlike in the blobpool), data-availability sampling can be safely layered on top, extending the sampling window to the whole slot and enabling blob throughput to scale. As such, the proposed mechanism can be seen as an alternative to blobpool sampling mechanisms (e.g vertical sharding, horizontal sharding) capable of achieving the same throughput scaling while also providing:
- to users: strong censorship resistance guarantees, possibility to acquire blob space in advance, loosening of mempool restrictions for blob txs.
- to the protocol: clear load bounds and a smaller critical-path propagation window, which mitigates the free option problem.
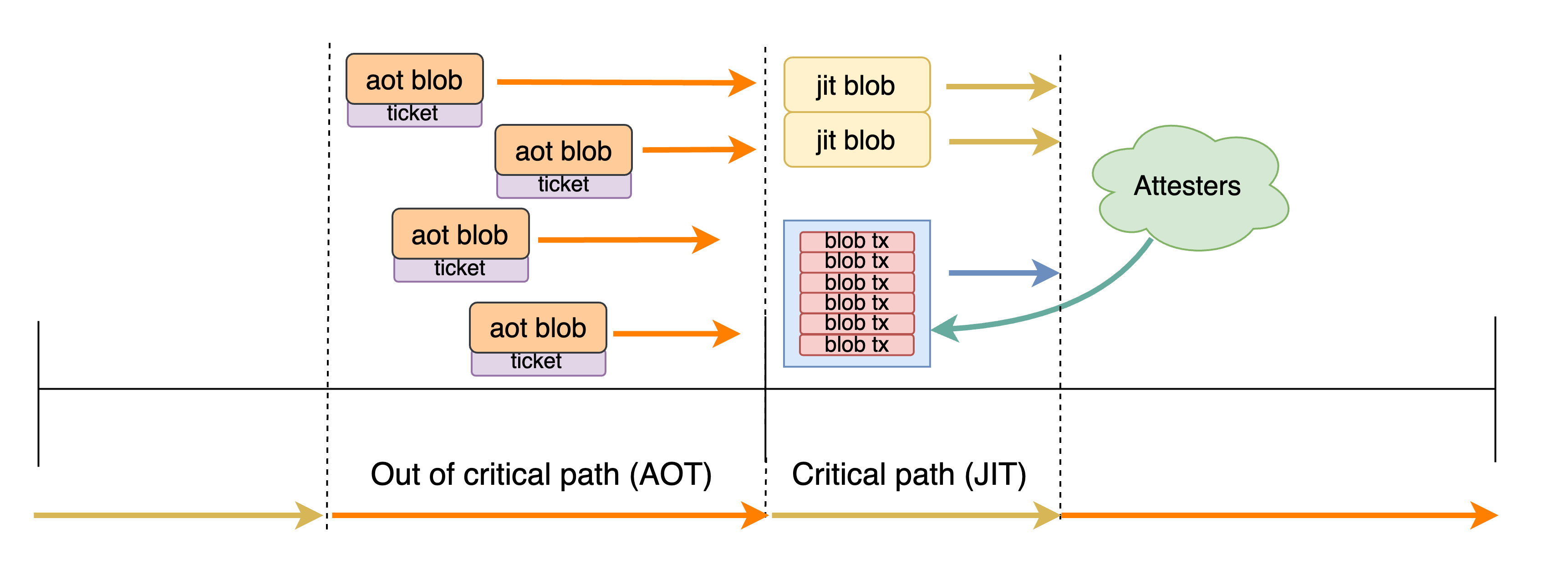
Figure 2. Two-lane view of a slot. AOT blobs pre-propagate before the critical path, spread over time; JIT blobs propagate within the critical path alongside the payload. Attesters verify availability of all blobs.
A ticket-based design could power both JIT and AOT blobs. However, we choose to retain the existing JIT path, where capacity is spot-priced rather than allocated with tickets, to accommodate use cases that do not involve ahead of time capacity planning, such as (pure) based rollups and eventually blob usage by the L1 itself (blocks-in-blobs, native rollups).
Before digging into the specifics of the mechanism, let’s expand on why it is worth it to introduce an AOT lane, by looking at the supply and demand side of AOT and JIT blobs.
The protocol’s perspective (supply side)
The AOT blob throughput that the system can provide is meaningfully higher than pure JIT throughput, because JIT blobs must propagate within a narrow time window, constrained by:
- The next proposer’s and builder’s need to determine availability before acting
- The free option problem, which becomes worse the longer we make this window
This creates bandwidth surges during the propagation window while leaving bandwidth effectively unutilized during the remainder of the slot. With pre-propagation from AOT blobs, propagation spreads over a larger time window (see Figure 2), smoothing bandwidth consumption and avoiding bottlenecks. Effective pre-propagation can achieve steady bandwidth usage at capacity, translating to increased throughput.

Figure 3. Illustration of bandwidth variation throughout slot in JIT vs AOT blobs. JIT blobs require bandwidth over smaller time periods leading to a more spiky consumption while AOT blobs’ propagation is spread out leading to smoother bandwidth consumption.
The user’s perspective (demand side)
The main use case for JIT blobs for rollups is synchronous composability with L1, which requires based sequencing as well as real-time proving. In contrast, externally sequenced rollups, as well as based rollups with preconfirmations (see for example Taiko), can make use of AOT blobs.
There might also be a hybrid design of based rollups that combine both preconfirmations and synchronous composability, essentially by using preconfs during most of the L1 slot but switching to based mode during the period of L1 block production, such that synchronous interactions are possible in this period. Such rollups might utilize a mix of JIT and AOT blobs, with JIT blobs being necessary in the period of L1 block production, to enable synchronous interactions with the L1.
Crucially, JIT blobs become significant for the L1 as well, once we look ahead to the future we’re rapidly moving toward, where zkEVM + DAS are used to scale the L1 itself by placing its payload into blobs, essentially turning the EL into a validity rollup.
Even with these use cases in mind, it is hard to argue exactly how the JIT vs AOT blob demand will shape up in the future. We know synchronous composability is beneficial, but how beneficial exactly? We know it is costly, but how costly exactly? We know that L1 will need JIT blobs, but what portion of the total blob throughput will it consume?
We argue that we do not need to be able to precisely predict the future demand of these two blob types in order to determine whether it is worth it to introduce more machinery for AOT blobs in the protocol. As long as there is meaningful demand for AOT blobs (which seems very likely, as not all rollups will want to be fully based, and even a hyperscaled L1 is unlikely to consume all blob throughput), all blob users benefit from moving AOT blob throughput into its own lane. As argued above, AOT blobs can make use of bandwidth outside the critical path that is currently left unused. Letting them use those resources frees up the critical path for JIT blobs. This means that introducing AOT blobs benefits not only users who consume them, but also users of JIT blobs who gain access to more of the constrained critical-path resources.
Design
We now describe the design, starting from the existing blobpool and building toward the full two-lane architecture.
Recap: blobpool tickets
Today, pre-propagation happens through the EL blobpool, but without any in-protocol mechanism to allocate propagation bandwidth. As blob throughput grows, the blobpool necessarily fragments — it has no global way to curb inflow, and thus can only do so locally, at the node level. Moreover, the blobpool does not benefit from data-availability sampling, and introducing it is challenging: the blobpool’s security model relies on only propagating valid, includable transactions, something which is hard to ensure when sampling, as a sampling node cannot fully verify blob availability by itself.
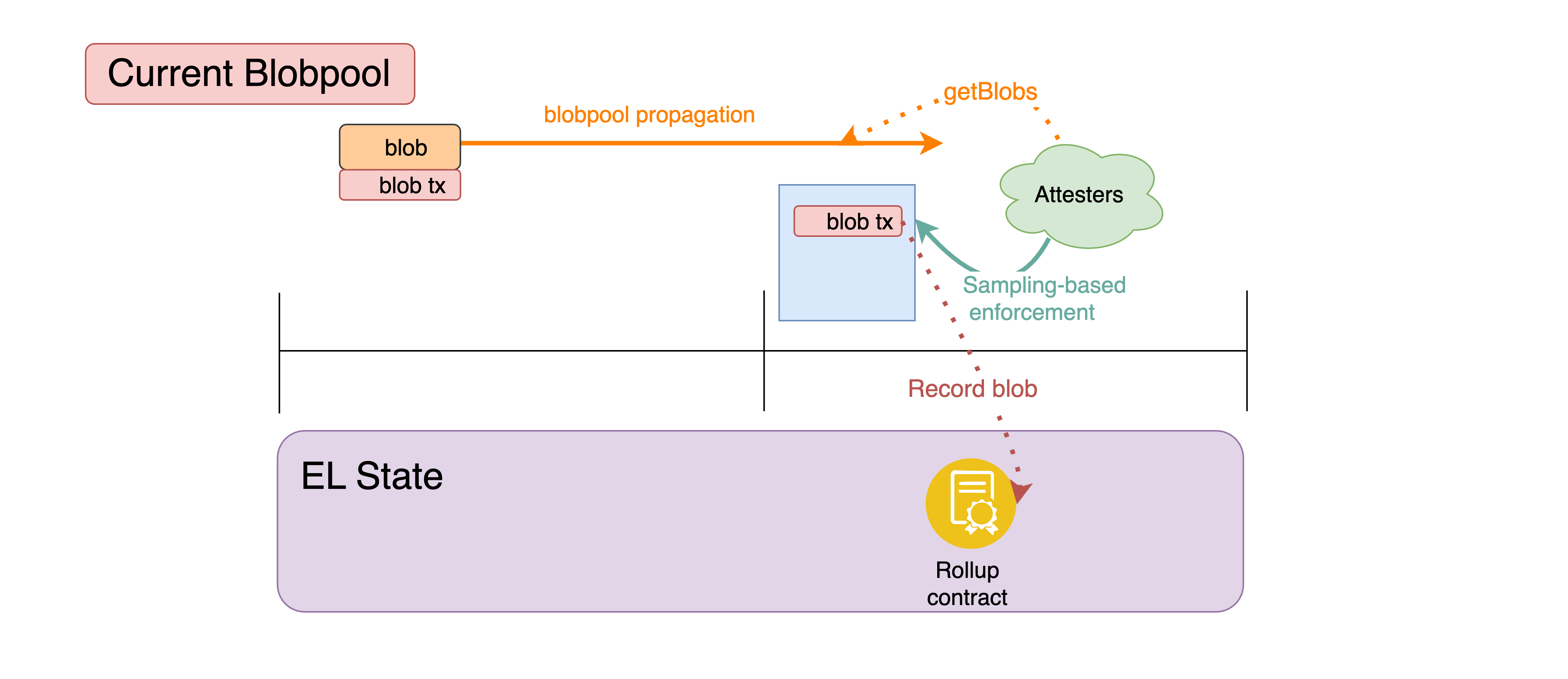
Figure 4. Pre-propagation in the blobpool today. Note that the blob transaction has to be propagated in tandem with the full blob data since availability of the latter is a validity criterion for the former.
Much has been written about blob ticketing mechanisms (see here, here, here), that propose to auction the right to propagate a blob. Recently, a blobpool ticket mechanism was proposed as a step in this direction, augmenting the blobpool to ensure DoS resistant pre-propagation of blobs in the blobpool, and retaining such a guarantee even if implemented alongside a blobpool sampling mechanism (see vertically sharded mempool and EIP-8070: Sparse Blobpool).
In order to submit and propagate a blob in the blobpool, a submitter would be required to hold a valid ticket, acquired by interacting with a designated ticket contract (for example implementing a first-price auction). This would ensure a limit on the number of blobs propagated through the blobpool, and fairly allocate the limited space. Because blobpool admission is now controlled by pre-paid tickets rather than by validity checks, sampling could also be safely introduced — nodes no longer need to verify full blob availability to decide whether to propagate a transaction.
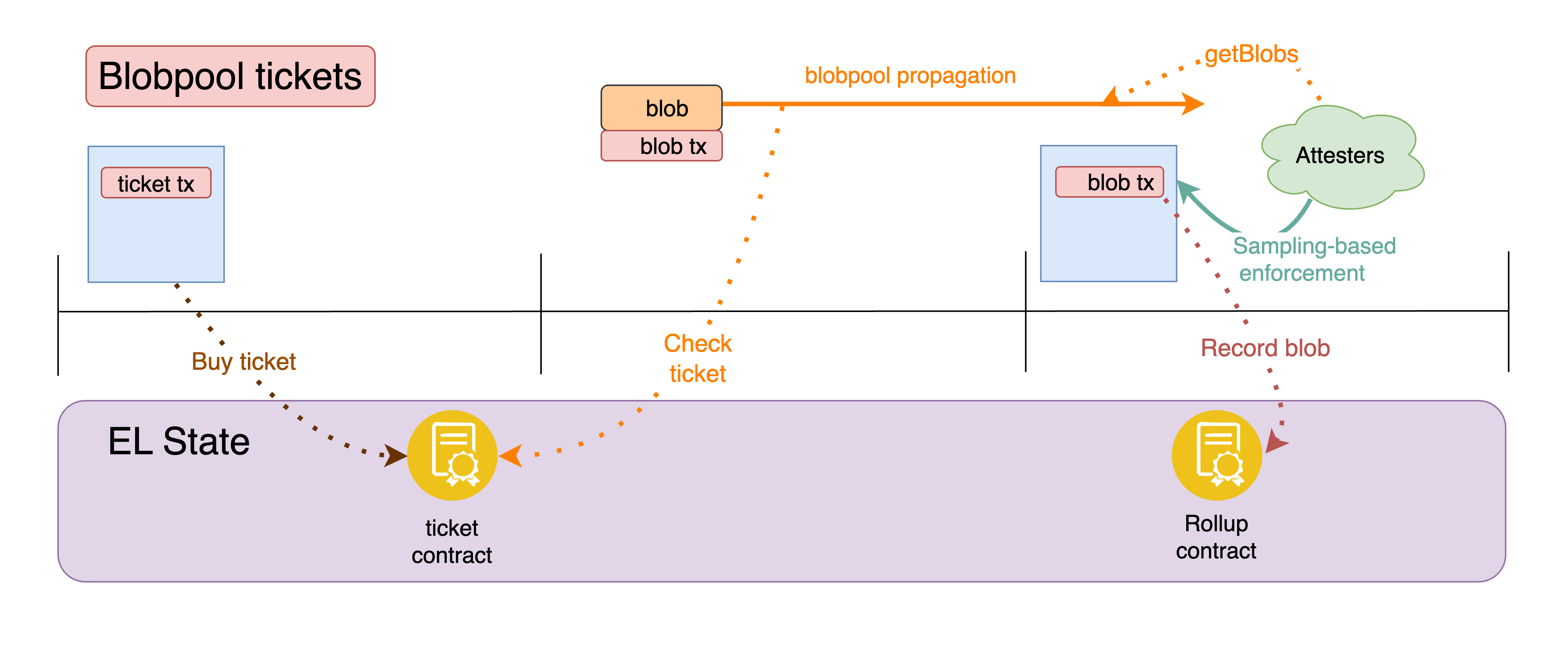
Figure 5. Augmenting the blobpool with blobpool tickets.
Blob tickets
Blob tickets take the ticketing concept further, moving pre-propagation to the CL and more deeply integrating it into the data availability pipeline. This differs from blobpool tickets in two key ways:
- For AOT blobs, a ticket is all users need to get a blob included on chain. In particular, AOT blob txs do not pay a blob basefee when included; they only pay regular gas fees. Hence the name blob tickets instead of blobpool tickets — what you’re buying with a ticket is actually blob space, not just blobpool space. From the protocol’s perspective, this is because propagation is where we actually consume scarce bandwidth resources. (JIT blobs are discussed later and remain spot-priced.)
- Propagation moves to the CL, reusing its already developed infrastructure for DA sampling, which would otherwise need to be unnecessarily duplicated on the EL. Moreover, DA sampling is fundamentally part of the consensus mechanism, because DA is a precondition to importing a block into the fork-choice. Today, we instead stitch together EL pre-propagation and CL availability enforcement with the
getBlobsengine API call.
The workflow with tickets is:
- Buying a ticket: By sending a transaction to the ticket contract, the user can acquire the right to propagate a blob at some point in the future.
- Propagation:
- Blob: Using the ticket (at the specified time), the user pushes blob data through the CL sampling infrastructure.
- Blob tx: Also using the ticket, the blob tx (without blob data) goes to the regular mempool.
- Inclusion and availability enforcement: When a blob tx is included, attesters enforce availability of the associated blobs (identified by
blob_tx.versioned_hashes), exactly as today.
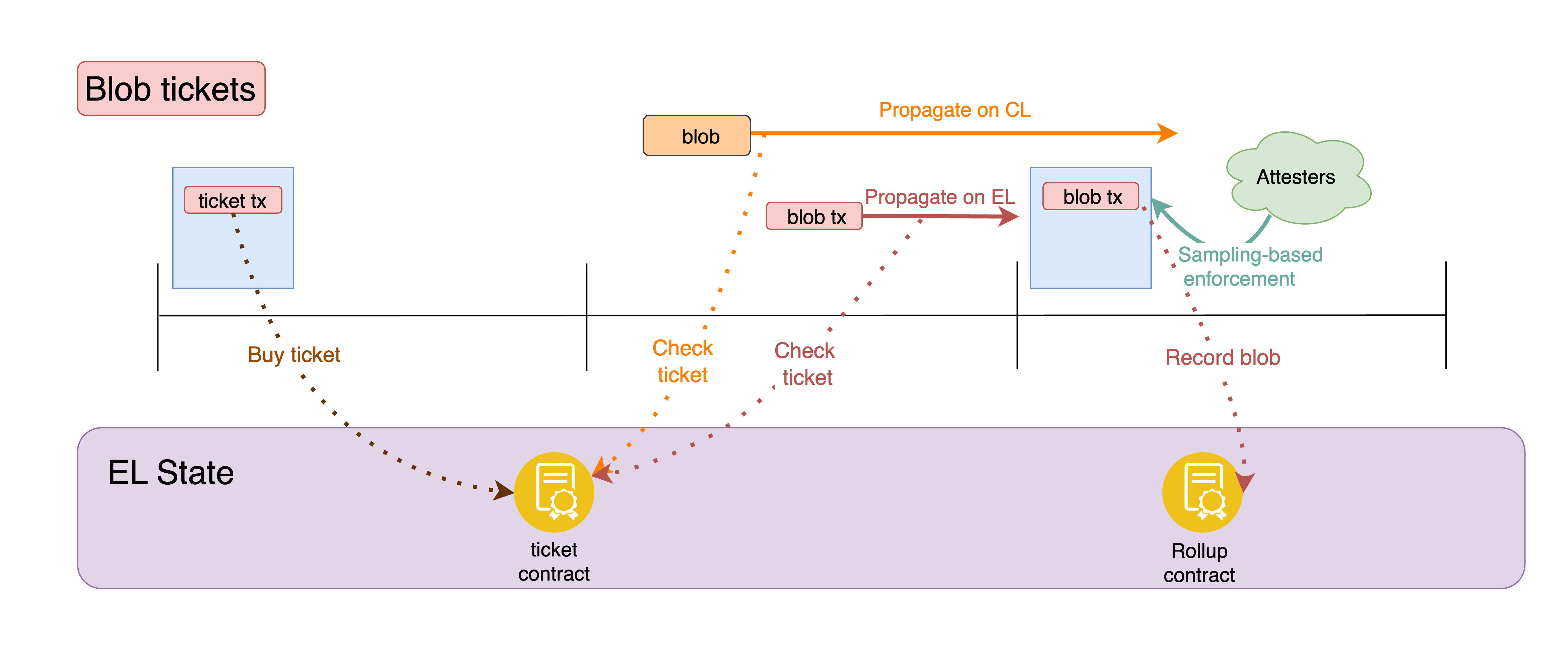
Figure 6. User workflow with blob tickets. The user acquires a ticket, propagates the blob on the CL, and submits a blob tx to the EL mempool. Once included in a block, a blob tx functions exactly as today, conditioning block validity on availability of the related blobs and thus giving the user strict availability guarantees.
Each ticket grants the right to propagate:
- One blob on the CL (propagation right)
- Multiple blob txs on the EL. For example up to 16, matching the max number of blob txs (
maxTxsPerAccount) currently allowed by the Geth blobpool, as well as the default maximum number of guaranteed mempool slots for regular txs in the Geth mempool (AccountSlots). Except, the limit here is per ticket, not per account.
These two rights are independent — the CL and EL each track ticket usage separately. This means a ticket holder can propagate their blob data on the CL and their blob tx on the EL in parallel, without coordination between the layers. Allowing multiple blob txs to propagate in the EL mempool with a single ticket lets users do resubmissions without purchasing another ticket, for example in case of base fee changes that invalidate the transaction.
User-note: Tying blob tx propagation to tickets, rather than to their validity, lets the mempool do without the strict rules that it currently applies to them. In particular, the same address can be allowed to queue up many blob txs in parallel, because one tx invalidating the others isn’t a concern — again, the right to propagate is about the ticket, not about validity! This is a concrete pain point for blob submitters, which if unaddressed is only going to get worse as throughput of individual L2s increases, since the cap on the number of blobs per tx will lead to an increase in the rate of txs from each L2.
The hybrid design: AOT + JIT
Given what we have discussed so far, AOT and JIT can in principle be structurally the same: we could design the system so that all blob capacity, including critical-path capacity, is sold via tickets. In such a system, the distinction between JIT and AOT would be purely about propagation timing.
That ticket-only design works well for the blob demand of actors who can plan throughput and buy tickets ahead of time, like operators of externally sequenced rollups. However, it breaks down once demand includes open user flow with no canonical ticket manager: users cannot be expected to source tickets ahead of time, and making builders intermediate tickets by default creates inventory, capital, and centralization pressure. In demand spikes, ticket inventory can become the bottleneck even when the network still has critical-path propagation capacity. This applies not only to L1 itself once it eventually uses blobs (blocks-in-blobs), but also to based rollups.
For this reason, the final architecture in this post is explicitly hybrid, introducing ticket-based AOT blobs alongside a spot-priced JIT lane. End users can then show up with transactions and directly pay for critical-path blob resources (JIT blobs, via blob basefee), while planned flow (AOT blobs) can use tickets (and benefits from doing so). In the payload, this separation is made explicit by introducing two lists of versioned hashes:
jit_versioned_hashes: for blobs that the builder commits to just-in-time. They are propagated (sampled) alongside the payload and pay for their resources immediately (through a JIT blob basefee set equal to \text{bf}^{AOT} - see the section of the ticket contract for more details), exactly like today’s blob lane.aot_versioned_hashes: blobs that were pre-propagated with tickets, now being asserted as available. The payment for blob resources has already happened when purchasing the ticket, no immediate payment is required.
Both lists condition the payload’s validity on availability: all blobs corresponding to jit_versioned_hashes and aot_versioned_hashes must be available in order for the payload to become canonical. The difference is only how propagation resources are paid for and consumed.
In summary, the network’s propagation resources have been explicitly split into two buckets: critical path and outside the critical path. Different markets govern the allocations of the two resources: an ahead-of-time onchain ticket auction for pre-propagation capacity, and a just-in-time spot market for critical-path propagation, where the builder has ultimate inclusion power.
The JIT mechanism is the same product as today’s blob lane: critical-path propagation, builder-driven inclusion, and spot payment via blob basefee at inclusion. Note however that since there is no blobpool pre-propagation for JIT blobs, users will have to communicate their blobs directly to builders. As such, JIT blobs correspond to today’s private blobs. The AOT mechanism is additive, providing an additional pathway with different properties: ahead-of-time ticket purchase, pre-propagation and therefore higher capacity, and, as we will see, censorship resistance (CR) guarantees. This path becomes the default for any blob that can be pre-propagated.
JIT vs AOT capacity
A fundamental question that arises in the hybrid design is about the resource split: how much of the network’s capacity to propagate blob data do we want to devote to JIT blobs and how much to AOT blobs? We propose a design where capacity constraints are governed by three parameters, which have to be set much like the blob gas target and limit are set today:
- B_1 (JIT max): the maximum number of JIT blobs per slot. This is an upper bound determined by how long we are willing to make the critical path — and correspondingly, how large a free option window we tolerate.
- B_2 (blob (JIT + AOT) max): the maximum total number of blobs per slot, an aggregate limit for JIT + AOT. This is determined by the network’s total propagation throughput over the course of a slot.
- R \leq B_1 (reserved JIT capacity): a portion of JIT capacity that is protected from AOT usage.
These parameters induce the following rules for a given slot n:
- AOT ticket sales: Up to B_2 - R tickets can be sold for a future slot. Since R is reserved for JIT, at most B_2 - R blobs can be scheduled ahead of time.
- JIT capacity: If a \leq B_2 - R AOT blobs have been scheduled for slot n, then up to \min(B_1,\, B_2 - a) JIT blobs can be included. This guarantees at least R JIT capacity, and allows JIT to expand up to B_1 when AOT demand is low.
B_2 is purely a technical constraint, reflecting the network’s total propagation budget over a slot. B_1 requires more discretion: it is bounded by the slot structure but may be set lower to limit the free option window. However, B_1 is not opinionated about JIT vs AOT — all capacity beyond R is shared, so a higher B_1 simply lets JIT expand further into the shared pool when AOT demand is low.
The most interesting design choice is R. The unreserved capacity B_2 - R is a shared pool usable by both AOT (via tickets) and JIT (if AOT demand leaves room). Setting R too low risks underserving JIT needs, which is particularly problematic once the L1 itself relies on JIT blobs. Setting R too high pushes capacity that could have been sold as tickets into the JIT-only path; the reserved capacity is never fully lost — any AOT activity can in principle use a JIT blob — but users are forced to go through builders directly and lose the protocol’s censorship resistance guarantees.
Baseline pricing
As a baseline, the existing blob base fee update mechanism can be applied just as today. Given the outlined limits, \min(B_1,\, B_2 - a) + B_2 - R blobs can be sold in the slot, \min(B_1,\, B_2 - a) as JIT blobs for the current slot and B_2 - R as tickets for a future slot. At most B_1 + B_2 - R blobs can thus be sold, in the case that a low number of AOT blobs were scheduled for the slot. The blobSchedule.target could be situated at B_2\times2/3 and blob_gas_used computed from the total number of JIT blobs and AOT tickets sold in the slot, multiplied by GAS_PER_BLOB. In practice, we would also add to the blobSchedule the new variables B_1, B_2 and R, which impose the more granular capacity constraints that the overall mechanism demands.
Ticket contract and pricing mechanisms for higher throughput
As mentioned earlier, in order to buy a ticket a transaction is sent to a dedicated ticket contract. The contract has two main functions, it outputs new tickets and updates old tickets if they got used or expired. The ticket contract outputs AOT tickets according to the aforementioned capacity constraints. Tickets are priced according to a the AOT base-fee, \text{bf}^{AOT}, in turn set by a target AOT blob capacity through a EIP-1559 type controller mechanism. As we noted earlier the base fee for JIT is set equal to \text{bf}^{AOT}.
Concretely this means that \text{bf}^{AOT} increases or decreases from slot i to slot i+1 if more or , respectively less, tickets are sold than \text{AOT}_{\text{target}}. Here \text{AOT}_{\text{target}} is a function of the AOT blob capacity B_2 - R e.g \text{AOT}_{\text{target}}=B_2 - R. The update rule for the base fee could be exactly the same as used for EIP-1559:
where \text{AOT}_{i} is the number of tickets sold in slot i.
Each ticket transaction needs to specify four variables base_fee, auction_bid,number of tickets — from which the contract can deduct auction_bid_per_ticket=auction_bid/number of tickets, base_fee_per_ticket= base_fee/number of tickets — and sender_adress which specifies the address getting the tickets. For the ticket transaction to be eligible to aquire tickets the condition base_fee_per_ticket\geq\text{bf}^{AOT} needs to be satisfied. Transactions are then ordered by decreasing auction_bid_per_ticket and tickets are allocated up to a limit of at most 2\times(B_2 - R).
In the case of overdemand (i.e if the total number of tickets users are trying to buy in a given slot exceeds the limit of 2\times(B_2 - R) both the base_fee and auction_bid of those transactions that acquire tickets is burned while the corresponding values of transactions that fail to acquire a ticket are returned to the senders address. Recall that the AOT blob throughput capacity is B_2 - R. Thus, all tickets (up to B_2 - R since we set the limit to twice the capacity) corresponding to transactions in the lower end of the ordered transaction list become valid for the next slot. For example let B_2 - R=5 and the following ordering of bidders in slot N. Alice: 3 tickets, Bob: 4 tickets, Charlie: 3 tickets. Then Alice will receive 3 tickets for the slot N+1, Bob will receive 2 tickets for slot N+1 and 2 for slot N+2 while Charlie will receive 3 tickets for slot N+2. In the case where demand does not exceed 2\times(B_2 - R), a value corresponding to \text{bf}^{AOT}\times number of tickets gets burned from each transaction.
Finally, note that there is no reason to only sell tickets for the next slot. Rather we could consider selling tickets in slot N which are valid for slot N+k. Being able to acquire tickets well in advance can have important benefits to L2s which can use this to more accurately price their own transactions given apriori knowledge of the price of a given blob. Determining the details of this — how large should k be? Should users be able to specify which slots they want tickets from a range of options ? — and so on is left as an open question at this point.
Censorship resistance
A key promise of the AOT lane is censorship resistance for blob txs. Tickets let us identify a restricted set of blobs whose availability can be established by a committee, so that they can be given inclusion guarantees — each ticket can be seen as also granting the role of inclusion list proposer, for a single blob. However, the base system with blob tickets alone does not fully deliver on this. In what follows, we identify the gap, show how recording availability onchain via a DA contract addresses it, and build end-to-end inclusion guarantees on top.
Limitations of blob tickets
Blob tickets are a very meaningful improvement, but leave a gap in the censorship resistance story. FOCIL is a censorship resistance mechanism that allows a committee to guarantee inclusion of certain transactions (for example taken from the mempool). However, blob tx validity depends on availability. Since availability hasn’t been recorded anywhere, inclusion of blob txs cannot be enforced. The root cause is that availability can only be determined at the moment of blob tx inclusion: even after a blob propagates and everyone has sampled it, there is no record of which blobs are available, and the only way to assert availability is through inclusion of a blob tx on chain.
Recording availability: DA contract
A clean way to address this is to record availability independently of blob tx inclusion. We introduce two changes:
- Payloads can contain versioned hashes independent of blob txs. A builder can include a list of versioned hashes for blobs whose availability it wants to assert, even without corresponding blob txs in the same block.
- Availability is recorded in a DA contract. At the start of each block, a system call records the versioned hashes from the payload into a DA contract. This creates a record of which blobs are available, queryable by nodes (as part of mempool and FOCIL participation) as well as within the EVM.
Enforcing availability works exactly like today: attesters only vote for blocks whose blobs are available. If a builder includes a versioned hash for unavailable data, the block won’t gain attestations. The only change is that versioned hashes can now come from the payload directly, not just from blob txs.
In addition, we adjust the onchain behavior of blob txs to work with the contract. Blob tx validity remains conditional on availability of the corresponding blobs, but to ensure this we now check the DA contract for availability of blob_tx.versioned_hashes, as part of validating blob_tx. In particular, we do not require blob_tx.versioned_hashes to be included in payload.versioned_hashes if they had already been recorded as available in a previous block. Availability only has to be established once.
Note: since the DA contract is queryable within the EVM, regular transactions can also check blob availability, for example a contract could condition its logic on whether a specific blob is available. Blob txs can remain the primary interface, but the DA contract opens the door to more flexible interactions with availability.
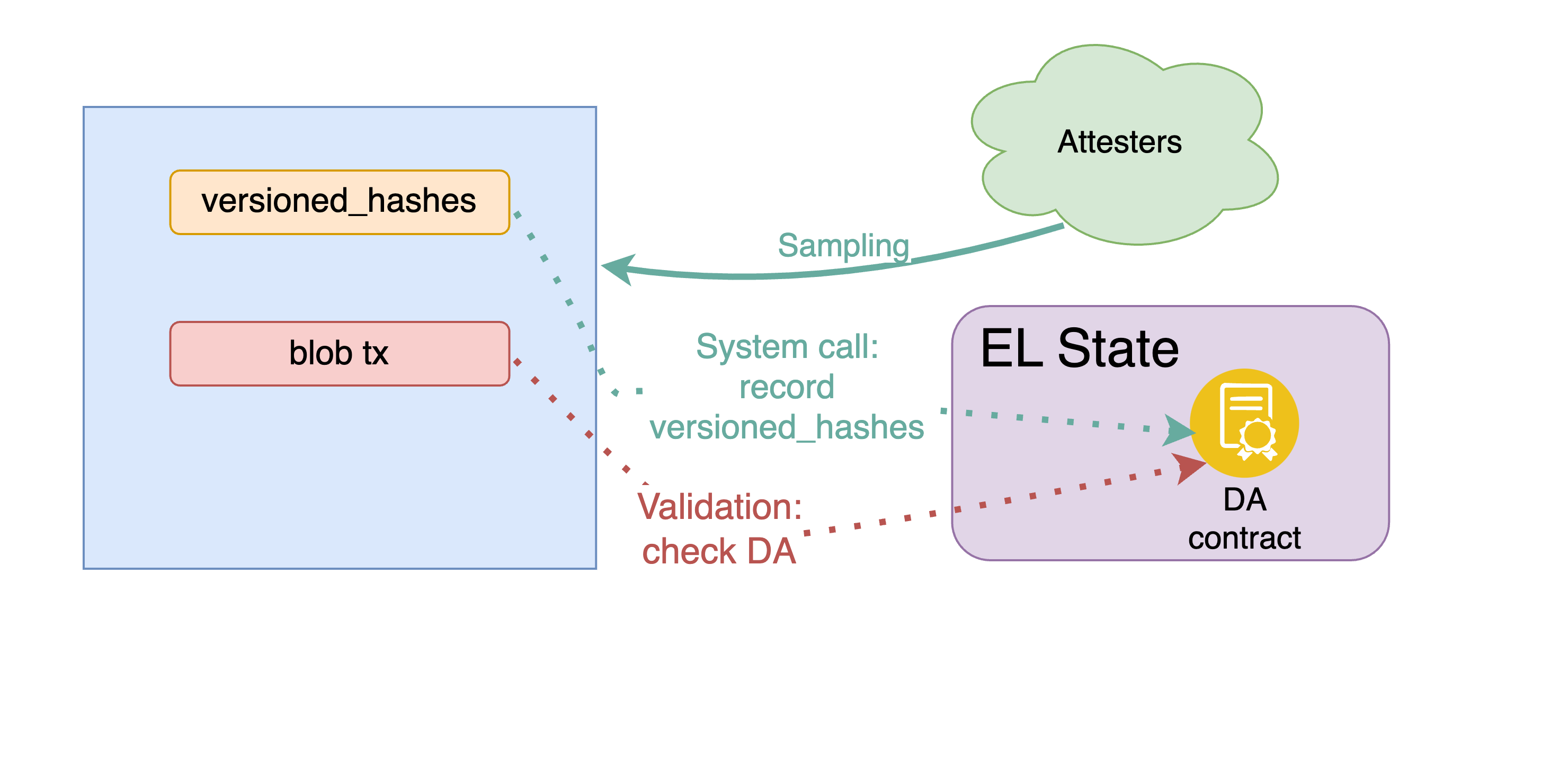
Figure 7. Availability recording and enforcement, and blob tx validity. The builder includes a list of versioned hashes referring to available blobs, whose availability is enforced through attestations. The versioned hashes are recorded in a dedicated DA contract, and blob tx validation checks availability in the contract.
Moreover, we adjust how we handle blob txs in the mempool, so that the mempool can benefit from the availability information in the contract. A blob tx can now propagate in the mempool if
either:
1. Availability is recorded: The referenced blobs’ availability is recorded in the DA contract, OR
2. Sender holds an unused ticket: The sender has a valid ticket that hasn’t been used yet on the EL (as seen locally by the node).
In other words, a ticket is only necessary if the blob tx is propagated prior to availability being recorded, e.g. in parallel with the blob itself. Once availability is recorded, a blob tx can propagate according to normal mempool rules, exactly like a regular tx. This also resolves a practical limitation of the base ticket system: without the DA contract, a ticket only grants a few blob tx submissions, and the mempool must restrict blob tx propagation to ticket holders. With availability recorded, these constraints disappear — resubmission, for example, does not need to be handled in any special way.
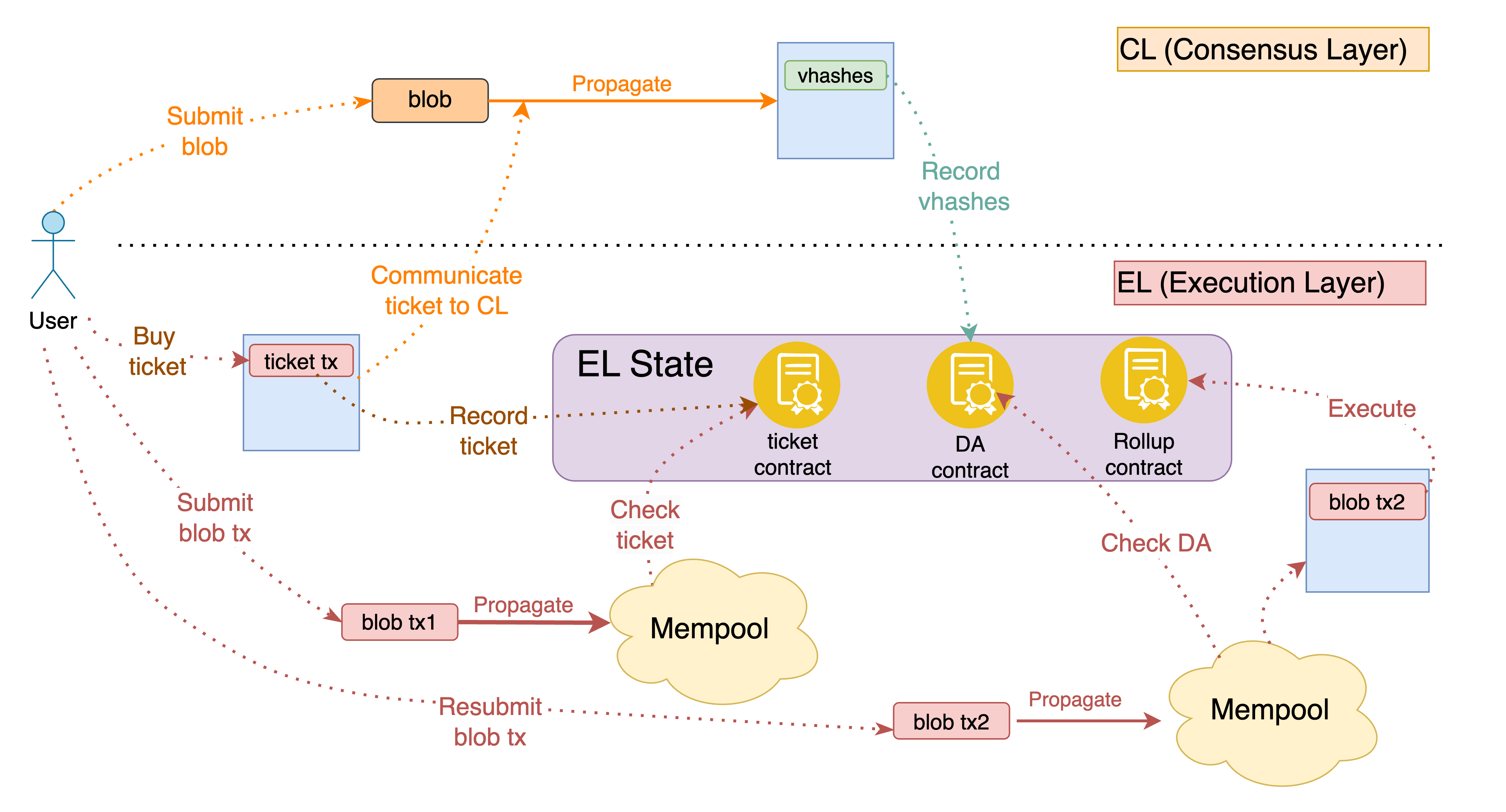
Figure 8. The full picture of blob and blob tx propagation with the DA contract. A ticket grants two independent propagation rights: one blob on the CL and a few blob txs on the EL. After availability is recorded in the DA contract, blob txs can propagate freely without tickets, enabling unlimited resubmission.
Full inclusion story for blob txs
With availability recorded independently of blob txs, we can now provide censorship resistance to blob txs, by first ensuring inclusion (availability determination) of blobs. We do so with a mechanism based on blob tickets, and adapting FOCIL-like fork-choice enforcement to blobs:
- Each PTC (Payload Timeliness Committee) member observes which blobs have been propagated by a deadline prior to block production. They sample these blobs and form a local view of availability.
- Members send lists of versioned hashes they observed as available.
- A majority vote determines which versioned hashes the proposer must include in the payload (and thus record in the DA contract).
- The proposer may include additional blobs but cannot exclude those the PTC requires.
- Attesters enforce this: they only vote for blocks that include PTC-required versioned hashes, unless the attester locally doesn’t see those blobs as available (safety always takes precedence).
Note that the proposer is now constrained from both directions when it comes to blob inclusions: they must include what the PTC requires (liveness) and cannot include what isn’t available (safety).
Crucially, once availability of a blob has been recorded, a blob tx referencing it becomes equivalent to a regular transaction, because its additional validity condition is guaranteed to be satisfied:
- As already mentioned, it can propagate without tickets, according to normal mempool rules
- It can be included through normal FOCIL
Moreover, ticket txs are themselves regular txs, benefitting from the same mempool and FOCIL infrastructure. Therefore, we get an end-to-end censorship resistance story for blob txs.
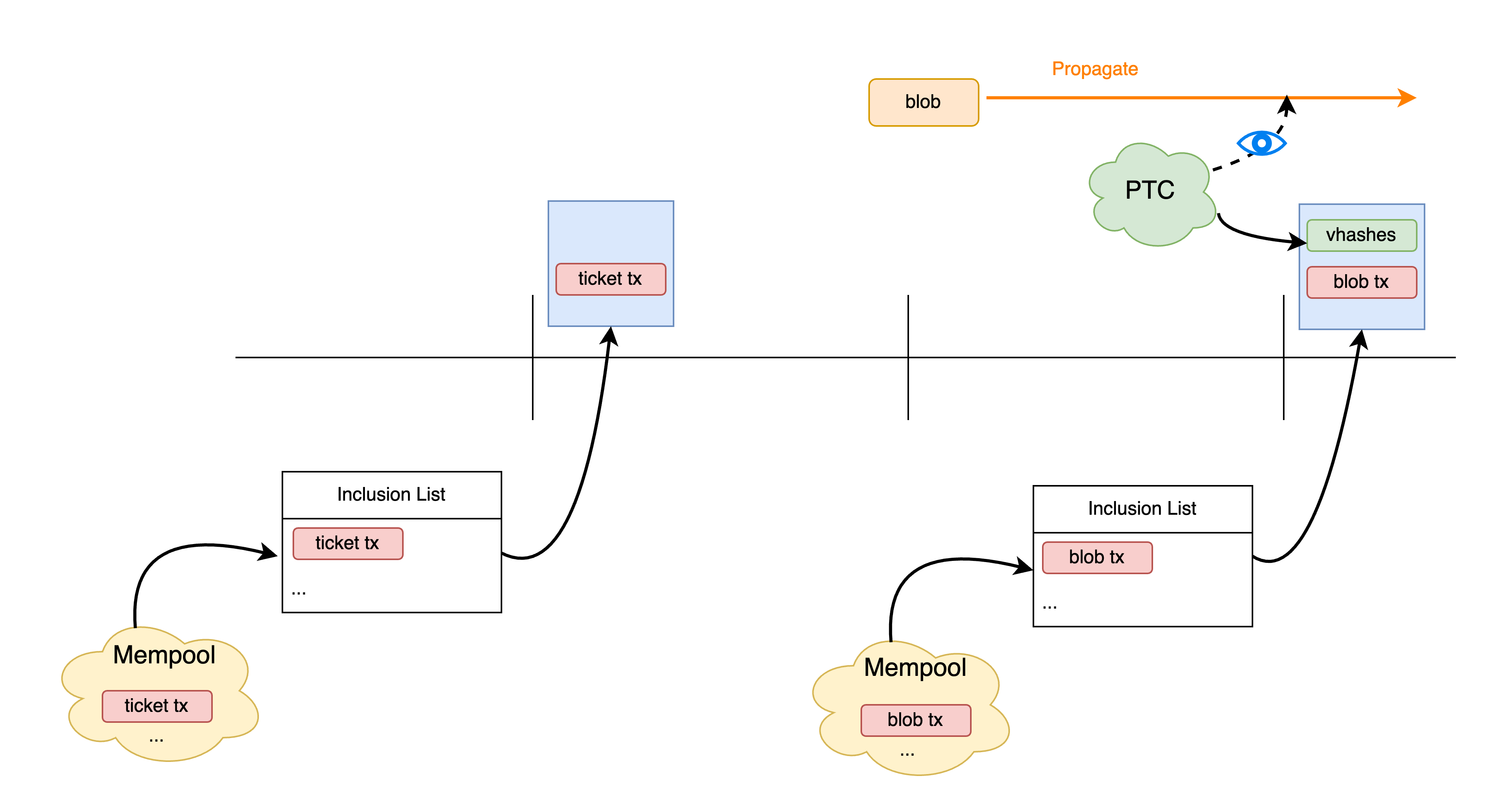
Figure 9. End-to-end inclusion guarantees for blob txs. The PTC enforces inclusion of propagated blobs (as versioned hashes recorded in the DA contract), while FOCIL provides inclusion guarantees for the ticket-buying and blob transactions.
Note that this end-to-end censorship resistance story applies to blob txs that use AOT blobs. Even an AOT blob propagated after the PTC deadline for a given slot can still receive inclusion guarantees from the next slot onward, as long as it remains available — this mirrors regular FOCIL behavior, where transactions not in the mempool by the IL (inclusion list) deadline cannot be force-included in the current block but can be in the next.
JIT blobs, on the other hand, are by definition only propagated when included in a block — there is no pre-inclusion propagation path, and therefore no way to determine their availability and guarantee their inclusion ahead of time. By the time a JIT blob is allowed to propagate, it is already included. We can think of JIT capacity as assigning a portion of the tickets (the “critical path” portion) to the proposer, who resells the right to the builder: inclusion is then entirely at the builder’s discretion (but incentivized by priority fees). For use cases that truly need JIT blobs — block and blob co-creation for synchronous composability — there is no alternative to having the builder do this, so the lack of inclusion guarantees is inherent. For use cases that don’t strictly need co-creation, a blob that fails to be included as JIT can always be re-submitted as AOT, gaining the full censorship resistance guarantees described above.
We conclude with a full picture of the design, contrasting it with today’s system.
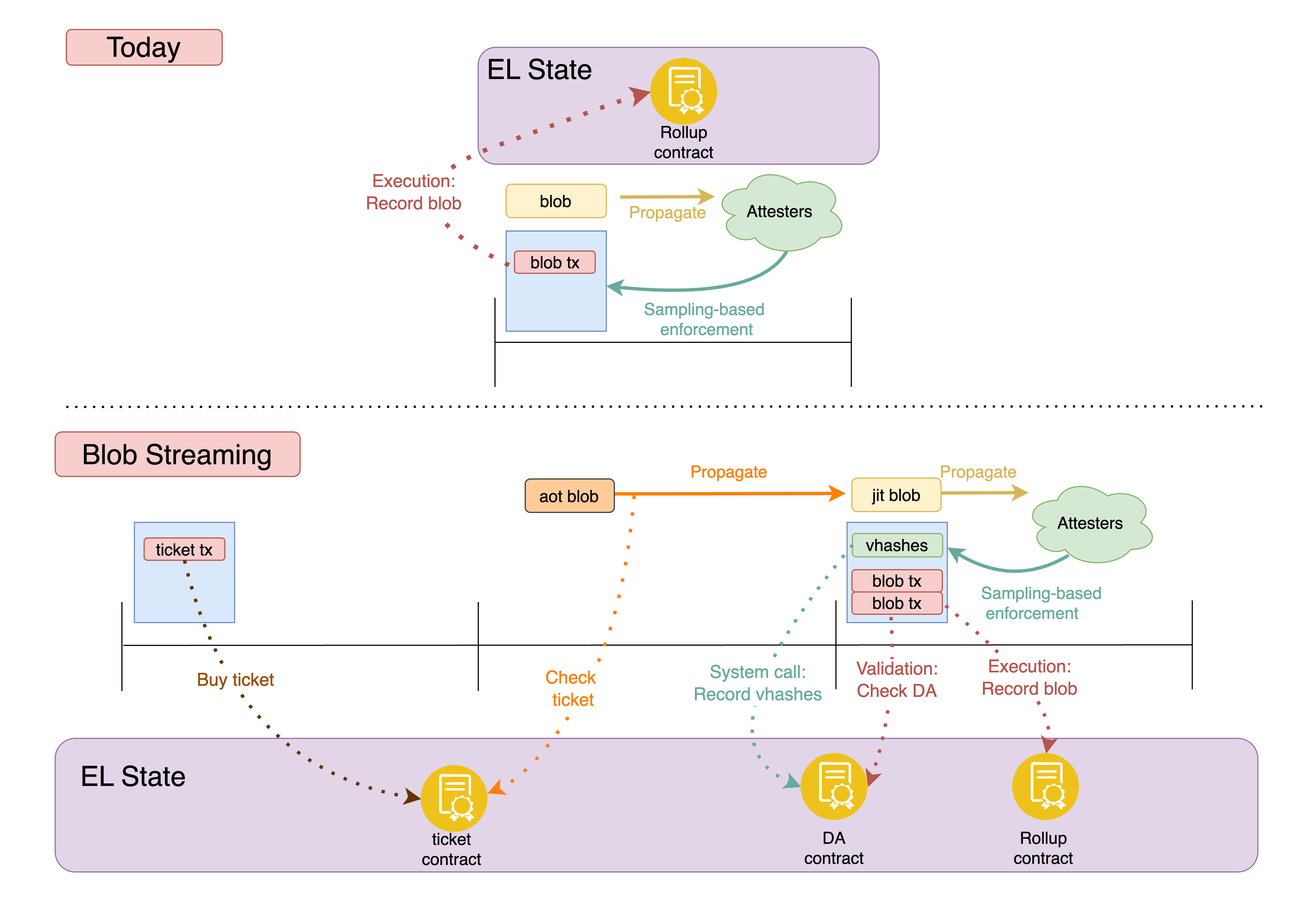
Figure 10. Today (top) vs Blob Streaming (bottom). Today, blob data, availability determination, and execution are coupled in a single block. With blob streaming, AOT blobs pre-propagate via tickets and are validated against the DA contract; JIT blobs propagate in the critical path as today. The DA contract records availability via a system call, after which blob txs are validated against it and execute normally.
Appendix
DA system contract
Design considerations
- Write pattern: At the start of each block, a system call records the versioned hashes of blobs whose availability is being asserted in that block.
- Read pattern: Contracts query by versioned hash to check if a blob is available. This should be cheap and simple.
- Storage management: Entries must be periodically deleted, to bound storage growth. At 128 blobs per slot, unbounded storage would grow ~10 GB per year.
- Current-block access: Transactions in the same block as availability recording must be able to check availability without external proofs, since they cannot produce proofs for data just recorded.
Contract design
The contract maintains a recent window (~128 blocks) via a ring buffer, enabling O(1) proof-free queries. This covers current-block access and typical rollup use cases.
Beyond that, users can prove inclusion against versioned_hashes_root stored in each block’s header. This keeps contract storage minimal while still enabling availability queries for a long period, arguably more than enough to make sure that a user can land a tx onchain after a blob’s availability has been determined.
Note that checking the DA contract as part of validating a blob tx is very cheap when the versioned_hashes are included in the current payload, since it’s a warm read — the versioned hashes were written to the DA contract at block start. The current usage pattern, with availability determination happening at the same time as execution, is then essentially unaffected.
# Constants
BLOCK_WINDOW = 128
MAX_BLOBS_PER_BLOCK = 128
RECENT_RING_SIZE = BLOCK_WINDOW * MAX_BLOBS_PER_BLOCK
# Storage
recent_vhs_buffer: list[Optional[bytes]] = [None] * RECENT_RING_SIZE
recent_availability: dict[bytes, int] = {} # vh => 1 if in recent window
recent_write_cursor: int = 0
def record_availability(versioned_hashes: list[bytes]):
"""Called via system call at block start."""
global recent_write_cursor
for vh in versioned_hashes:
# Clear old entry at current position
old_vh = recent_vhs_buffer[recent_write_cursor]
if old_vh is not None:
del recent_availability[old_vh]
# Record new entry
recent_vhs_buffer[recent_write_cursor] = vh
recent_availability[vh] = 1
recent_write_cursor = (recent_write_cursor + 1) % RECENT_RING_SIZE
def is_available(versioned_hash: bytes) -> bool:
"""Check availability in recent window (no proof needed)."""
return recent_availability.get(versioned_hash) == 1